Est-ce un hasard si nous avons attendu un livre sur le thème de l’addiction pour changer notre manière de faire des livres et employer des logiciels libres de bout en bout ? Pas sûr. En effet depuis la PAO nous nous sommes habitués à un flux de production devenu traditionnel et dont nous avons dit ailleurs à quel point il pouvait devenir problématique. Ce post raconte l’histoire d’une collection que nous désirions depuis un moment produire avec les techniques ouvertes du web. Car oui, on peut aussi fabriquer un livre dans son navigateur. Making-of.
Une collection neuve
Addiction sur ordonnance est le premier volume de la collection interventions. Petits volumes à petit prix et à pagination raisonnable (autour de 128 pages), cette collection aborde des sujets chauds d’actualité pour lesquels C&F Éditions peut apporter les lumières qu’elle sait apporter, avec toujours une forme originale et soignée. Vous pouvez le voir ici.

Le cœur de l’ouvrage est l’enquête de Patrick Radden Keefe « Un empire bâti sur la douleur », et est assorti d’un dossier. C’est le récit impressionnant de la résistible ascension de la famille Sackler, Arthur et ses frères, experts en marketing ayant acquis un petit laboratoire pharmaceutique et modifié sa production pour devenir milliardaires en vendant légalement la drogue la plus addictive qui soit : les opioïdes de synthèse. Ils ont abouti en quelques années au double résultat stupéfiant, si j’ose dire, d’une fortune colossale, agrémentée d’une image de philanthropes, et surtout d’une catastrophe sanitaire sans précédent avec plus de 400000 morts aux États-Unis. Et ce n’est pas fini, l’entreprise étant aujourd’hui en quête d’expansion sur le marché mondial pour étendre ses profits (et forcément ses dégâts).
Nous avions le projet depuis quelques années de développer une collection produite différemment, avec des outils ouverts et libres, et un flux de production plus collaboratif, qui permette par exemple de travailler en collectif très rapidement sur de petits ouvrages produits à chaud, au plus près de l’événement. Mais toujours dans l’urgence, il n’est pas si évident de faire de la R&D pour une petite structure poussée par son programme éditorial ambitieux et limitée par des moyens restreints. Mais nous avons finalement tenu la promesse que nous nous étions faite, et cet ouvrage inaugure le procédé. il faut noter que nous sommes également dans le même esprit que celui qui nous a fait élaborer la licence édition équitable qui défend les droits de nos lecteurs.
Des différentes manières de faire un livre
Enseignant l’édition dans le master d’édition de l’Université de Caen, je m’intéresse évidemment de très près aux différentes manières de faire des livres. Je rêve même de vous raconter tout ça un jour, car c’est un sujet passionnant et qui n’est vraiment abordé dans aucun manuel, à ma connaissance. En voici quelques unes, par exemple :
- On peut faire des livres avec des caractères en plomb dans un composteur, et les imprimer sur une presse typographique. Vous croyez que je plaisante ? Regardez ce que fait Jean-Renaud Dagon au Cadratin par exemple.
- On peut utiliser un outil de PAO WYSIWYG propriétaire comme InDesign ou Quark Xpress ou le nouveau venu Affinity Publisher, c’est la manière la plus répandue aujourd’hui.
- On peut aussi utiliser un outil de PAO sémantique propriétaire comme FrameMaker. Il était le roi du temps où on imprimait de gros manuels d’utilisation, qu’on glissait dans les emballages du matériel et du logiciel par exemple.
- On peut encore utiliser le logiciel libre balisé LaTeX. C’est l’outil de prédilection des scientifiques et des chercheurs pour leurs articles et thèses, et certains éditeurs l’emploient, comme O’Reilly ou Le Robert. C’est pointu, c’est sérieux et ça marche.
- On peut également utiliser le logiciel libre WYWIWYG Scribus, si on n’a pas trop de notes de bas de page. Il est prometteur, mais son développement est très lent et desservi par des bugs.
- À la fac, par exemple, nous utilisons le flux Métopes du pôle document numérique. Il est basé sur XML-TEI, permet de produire un fichier pivot pérenne et interopérable, tout en bénéficiant du savoir faire des maquettiste et de terminer la manifestation imprimée dans une maquette InDesign.
- Enfin (mais cet « enfin » ne concerne que cette petite liste partielle et ne clôt certainement pas les différentes manières de faire un livre), les CSS étant très au point, on peut utiliser le code html + css et tenter de générer un PDF, soit au moyen du logiciel propriétaire Prince, qui existe depuis une bonne dizaine d’années, et est assez efficace, soit au moyen du nouveau venu sous licence libre (MIT) : Paged.js. C’est cette toute dernière solution que j’ai choisi de tester pour réaliser ce livre, car j’avais envie de voir ce qu’on peut faire dans un navigateur web. Il existe d’autres logiciels dans cette branche, comme par exemple les outils HTML2PRINT produits par la talentueuse équipe OSP.
On pourrait et on devrait continuer ce panorama, et une page ressources a été ouverte par prepostprint. On pourra aussi se perdre dans la timeline réalisée par Julie Blanc.
La timeline de Julie Blanc.
Paged media
Paged.js est un ensemble de scripts javascript qui est destiné à compléter le fonctionnement des navigateurs web afin qu’ils supportent mieux les spécifications CSS du W3C pour réaliser des feuilles de styles destinées aux médias paginés. Ce genre de patch s’appele un polyfill. Il essaie de combler les trous, ce qui est d’autant plus nécessaire qu’il semble qu’un certain lobbying s’exerce au sein du W3C pour ralentir cet aspect (par exemple Håkon Wium Lie, le patron de Prince, logiciel propriétaire, a fait tout ce qu’il pouvait contre CSS Regions et obtenu son abandon). Car en théorie, on peut vraiment faire de la PAO correctement avec CSS, on y prend même goût et cela rend des outils comme InDesign bien laborieux et obsolètes.
Paged.js est donc produit par la Fondation Coko (pour collaborative knowledge) de Adam Hyde, gourou voyageur des Booksprints et des Flossmanuals. Qui cherche à produire des méthodes, des flux et des plateformes de production de publications, ciblant notamment le monde académique, mais pas que. Paged.js est ainsi une brique au sein d’un projet plus large : Editoria. Deux de mes amis ont rejoint sa petite équipe : Julien Taquet et Julie Blanc. Le développement est assuré par Fred Chasen. Tous deux sont extrêmement passionnés et compétents dans ce domaine, et on se retrouve parfois au sein du collectif Pre post print imaginé par Sarah Garcin et Raphaël Bastide, autres grands talents du design libre et alternatif. Voilà pour la photo de famille.
Bon, avant de me lancer, j’ai pris le temps de préparer la couverture avec Inkscape, logiciel libre très convainquant, et mérite qu’on y passe le temps d’apprentissage un peu rugueux qu’il demande, tout en restant proche de la PAO traditionnelle et du logiciel de dessin vectoriel concurrent que je ne nommerai pas.
La couverture dans inkscape.
Se lancer avec Paged.js
Le logo de Paged.js.
Avant de commencer, RTFM (Read the fucking manual) semble une approche nécessaire mais insuffisante : en plein développement, Paged.js ne bénéficie que d’une documentation assez sommaire. On peut télécharger l’outil sur le Gitlab de paged media. Et ainsi bénéficier du contact avec les développeurs.
Mon choix initial étant de respecter le précepte de Richard Stallman selon lequel il n’est pas si bien d’utiliser un logiciel libre sur un OS privateur, j’ai installé linux Xubuntu sur une machine virtuelle, ce qui est très bien pour commencer. Xubuntu a l’avantage d’être léger, sans effets graphiques, et très facile à installer. On peut avec VirtualBox créer facilement un pc virtuel sur un mac, si on ne dispose pas de PC. Cela permet d’apprendre le logiciel libre et de s’y essayer quand on est un graphiste, souvent équipé d’un mac. Les performances sont un peu moins bonnes que sur un petit PC. Ensuite il est toujours temps de passer sur une vraie machine. Je pourrai vous raconter ça dans un autre post si ça vous intéresse (signalez-le en commentaire) et Davduf a produit une très jolie Petite histoire d’une libération personnelle.
Cuisine et dépendances
Passons aux pages intérieures et c’est là le plus important. La plaie de bien des logiciels, ce sont les librairies et les dépendances qui rendent leur installation parfois plus douloureuse que leur utilisation même. Paged.js n’y échappe pas dans la mesure où il a besoin d’un serveur web. L’installation propose de le faire avec des modules node et il faut savoir jouer un peu du terminal pour installer ces derniers. Il faut notamment ledit petit serveur web qui peut s’installer par :
sudo npm install -g http-server http-server (start)
Puis on voit son projet
http://localhost:8080
Bref : git et npm sont des éléments qui semblent indispensables et demandent une petite culture du développement [edit : si vous avez déjà apache installé sur votre machine pour faire du http://localhost alors c’est inutile]. C’est dommage, car ensuite, coder un livre en html et en css est une chose assez logique et simple.
Julien Taquet propose une version prépackagée un peu différente de paged.js sous la forme d’un boilerplate qu’il a appelé bookstyler et qui repose sur grunt (une autre dépendance à installer ainsi :).
npm install -g grunt-cli
ensuite on se rend dans le projet, on lance la commande grunt et on peut accéder à son projet dans le navigateur web à cette adresse :
http://localhost:9000/dist/
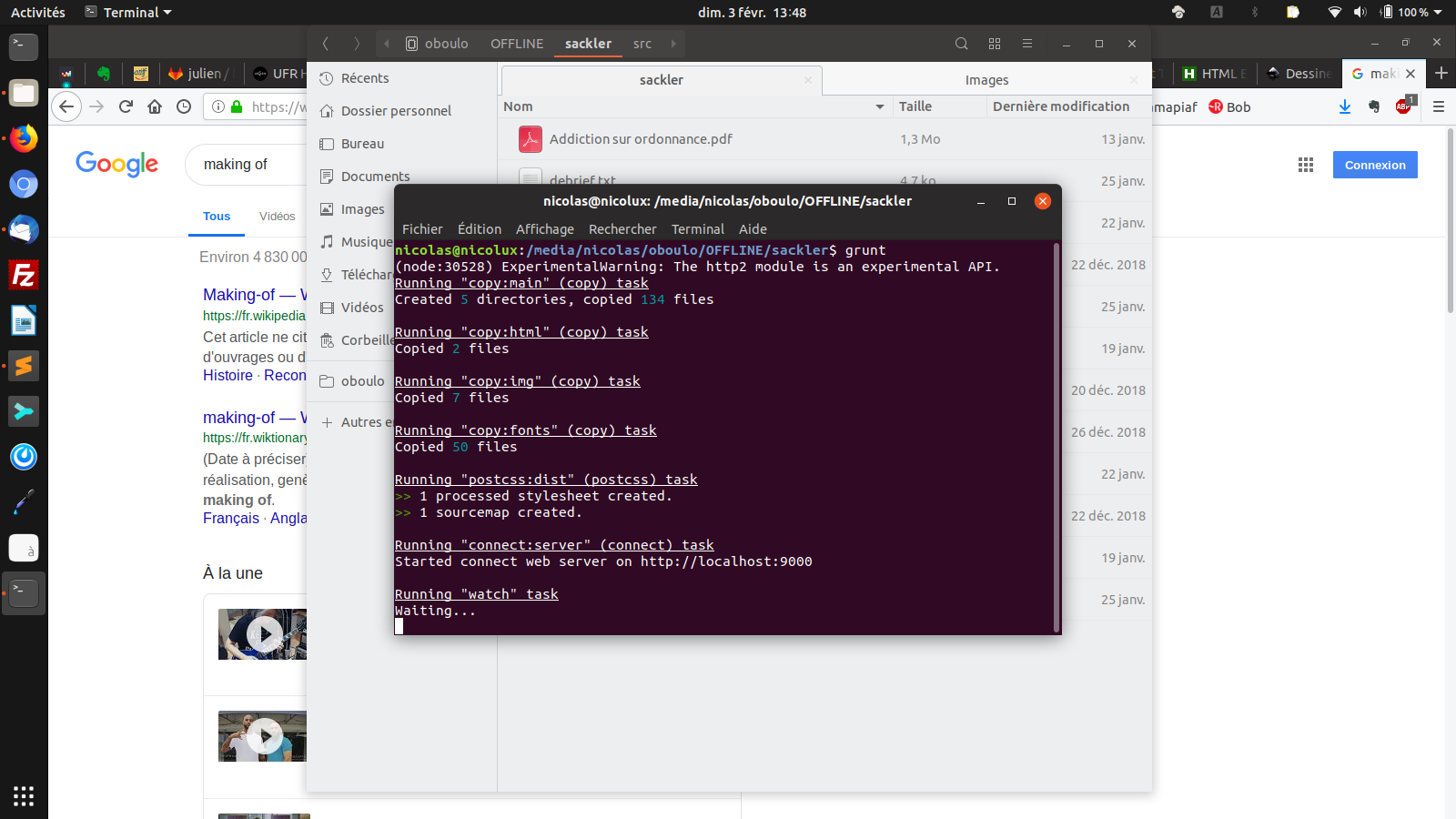
Il faut ouvrir un terminal pour installer certaines dépendances et lancer l’utilitaire Grunt.
Pour mon projet, j’ai choisi deux autres dépendances, typographiques celles-là, que sont les polices libres Zilla-Slab de peter Bil’ak et Nikola Djurek de Typotheque et le Chunk Five de Meredith Mandel.
À propos de ces dépendances, polices et scripts, j’insiste (contrairement à ce que dit Julien Tacquet dans son git) sur le fait qu’il est important de ne jamais recourir aux CDN (liens internet pointant ces ressources, collé dans votre code) mais de les télécharger et de les inclure localement dans votre projet. Les CDN posent plein de problèmes imprévisibles dans la chronologie de l’exécution du javascript et sont en général une mauvaise pratique d’un point de vue pragmatique, éthique et sécuritaire.
Paged.js a besoin aussi du navigateur Chromium, malheureusement, notamment pour l’export du PDF final, Firefox ne respectant pas le format de page défini par la CSS lors de cette étape. Il faudra aussi, hélas, passer par Acrobat pour ajouter des traits de coupe et convertir le produit final depuis l’espace RVB vers le noir et blanc (ou le CMJN selon le cas). Il existe peut-être d’autres moyens pour cela, mais je ne les connais pas et suis preneur de vos éventuels conseils.
Avanti, pas-à-pas
Une fois tout cela installé dans le projet, il suffit d’un éditeur de code (n’importe lequel, à votre goût, personnellement j’utilise Sublime text sous linux, mais on peut utiliser un IDE ou un simple éditeur de texte) et de commencer à baliser son contenu en html. Des sections, des titres, des paragraphes. Rien d’autre qu’une structure sémantique du texte. Il est important de comprendre que le html source n’est pas le html rendu dans le navigateur. Les scripts le transforment profondément, mais le fichier source lui-même n’est pas transformé. C’est dans la mémoire du navigateur que le fichier final demeure le temps de l’affichage. On peut ouvrir l’inspecteur pour voir les modifications profondes subies par celui-ci pour faire le livre.
Quelques détails : les notes doivent être insérées en ligne dans le texte au sein d’un élément span. Comme il s’agit d’un livre, il est important de contrôler un peu ses espaces. On peut utiliser des entités unicode pour les différentes espaces, cela fonctionnera si ces espaces sont incluses dans la police de caractères.
- espace insécable ou
- espace fine insécable  
Il existe quelques autres signes qui peuvent être encodés ainsi : tirets moyens (– –) et il faut veiller à utiliser de vraies apostrophes et non les chiures de mouche que l’éditeur de code ne manquera pas d’insérer à la place. Après quelques rechercher-remplacer, tout rentre dans l’ordre.
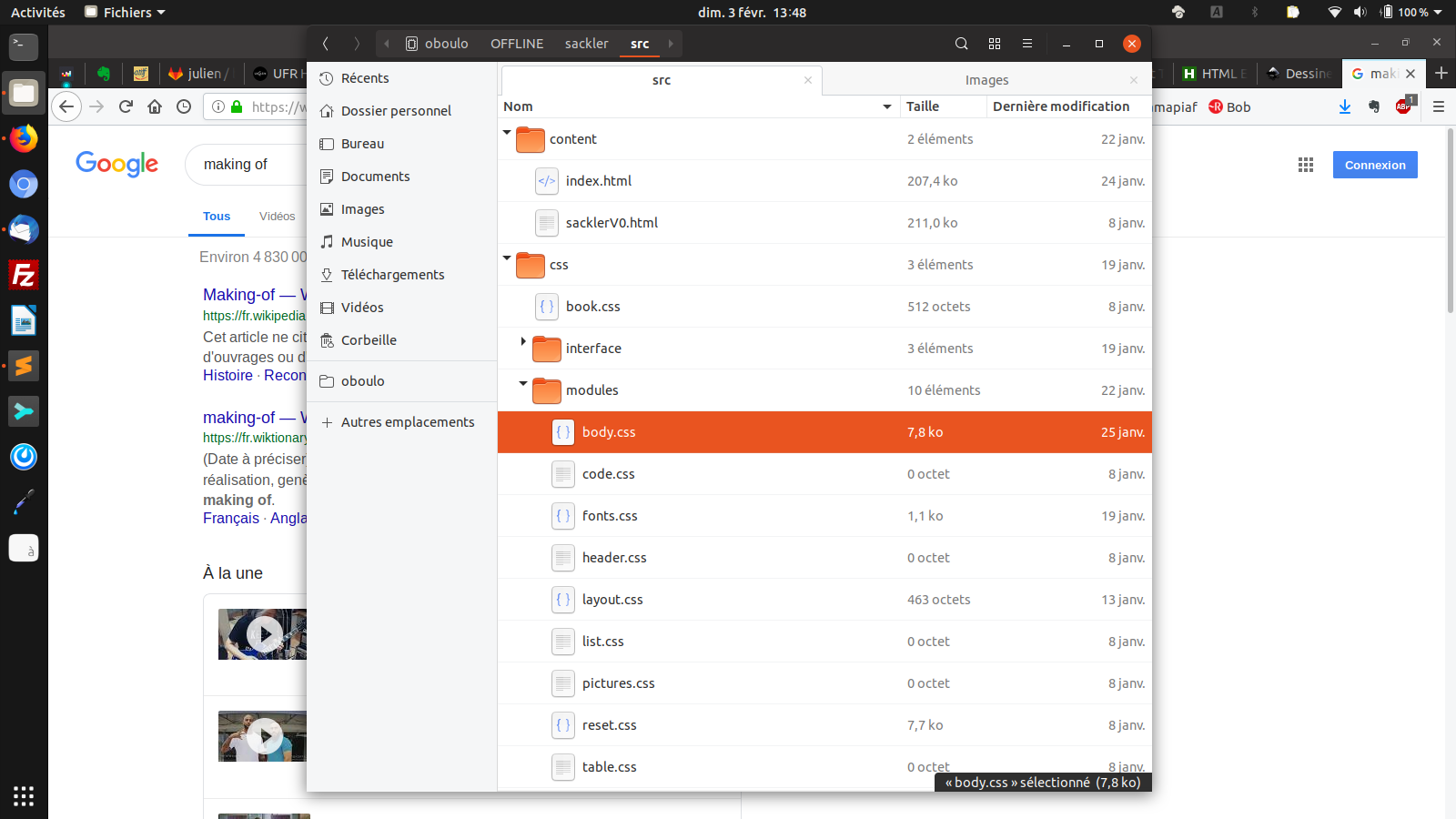
Dans le dossier source, on trouve le html et les feuilles de style découpées en modules spécialisés (body pour les styles du livre, fonts pour les polices, layout pour les formats de page et de marge).
Du côté de la CSS, on peut styler les éléments ou employer des classes. Julien Taquet a séparé la CSS en modules plus spécialisés, ce qui est bien pratique et il suffit d’éditer les préférences. Important, il m’a précisé que paged.js fonctionne mieux avec des tailles de polices en pixels. Attention toutefois, le pixel CSS est beaucoup plus gros qu’un pixel écran et cela ne donne pas des résultats très fins.
La vraie magie de Paged.js, c’est qu’il va faire marcher de bout en bout des classes et propriétés CSS comme
@page {
size: 140mm 200mm;
margin: 1in 2in .5in 2in;
}
On dispose aussi de différents gabarits de page et de tout un tas de zones dans la marge pour les titres courants, les folios etc. Les détails sont ici en attendant une documentation plus étoffée.
On peut aussi générer facilement du contenu par la CSS, par exemple les folios :
@page {
@bottom-left {
content: counter(page);
}
}
Et pour une table des matières toujours fraîche :
a.tdm::after {
content: ", page " target-counter(attr(href), page );
}
Il est possible de contrôler les sauts de pages ainsi :
h2 {
break-before: page;
break-after: avoid;
}
Il y a plein d’autres petits détails qui permettent facilement de contrôler sa maquette. Ça fonctionne bien.
Les seuls vrais problèmes sont liés à la gestion du texte de lecture lui-même. C’est amusant de constater que c’est la base qui pose le plus de problèmes, quand bien même on peut faire des choses très élaborées visuellement.
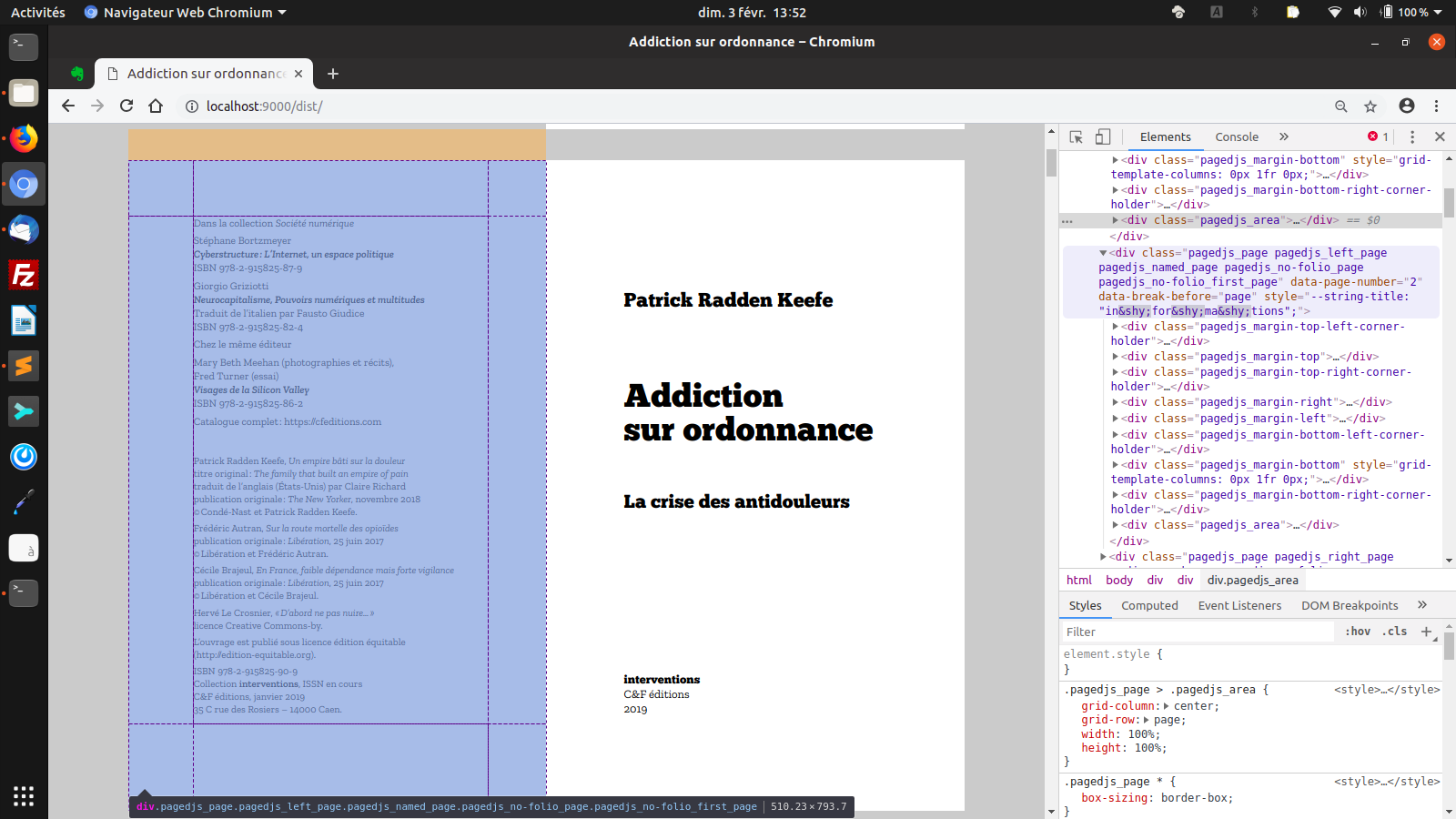
La page de titre avec l’inspecteur et les modifications du DOM effectuées par Paged.js.
En effet, la césure et la justification ne sont pas le point fort des navigateurs web. Même si les CSS proposent des propriétés pour les veuves, les orphelines, et la césure. Sous mac, Chromium sait un peu couper les mots, mais sous linux ce n’est pas le cas. On peut utiliser un script hyphenator, mais il faut le raffiner. J’ai eu du mal. En gros, ce script ajoute des traits d’union conditionnels partout dans le texte, et il faut le limiter un peu pour protéger les noms propres, etc.
Enfin, malheureusement, les notes de bas de page ne sont pas encore au point et donnaient trop de bugs de positionnement. J’ai dû y renoncer pour le moment, et opter pour… (malédiction) les notes de fin de section (gasp). Julien Taquet a fait une petite modification du script de gestion des notes pour que cela fonctionne. Je peux dire que je n’ai pas lâché l’affaire facilement et n’ai pas compté mes nuits, mais j’ai fini par lâcher. Il le fallait, car le projet n’était pas qu’un exercice de style, c’était un vrai livre qui devait paraître.
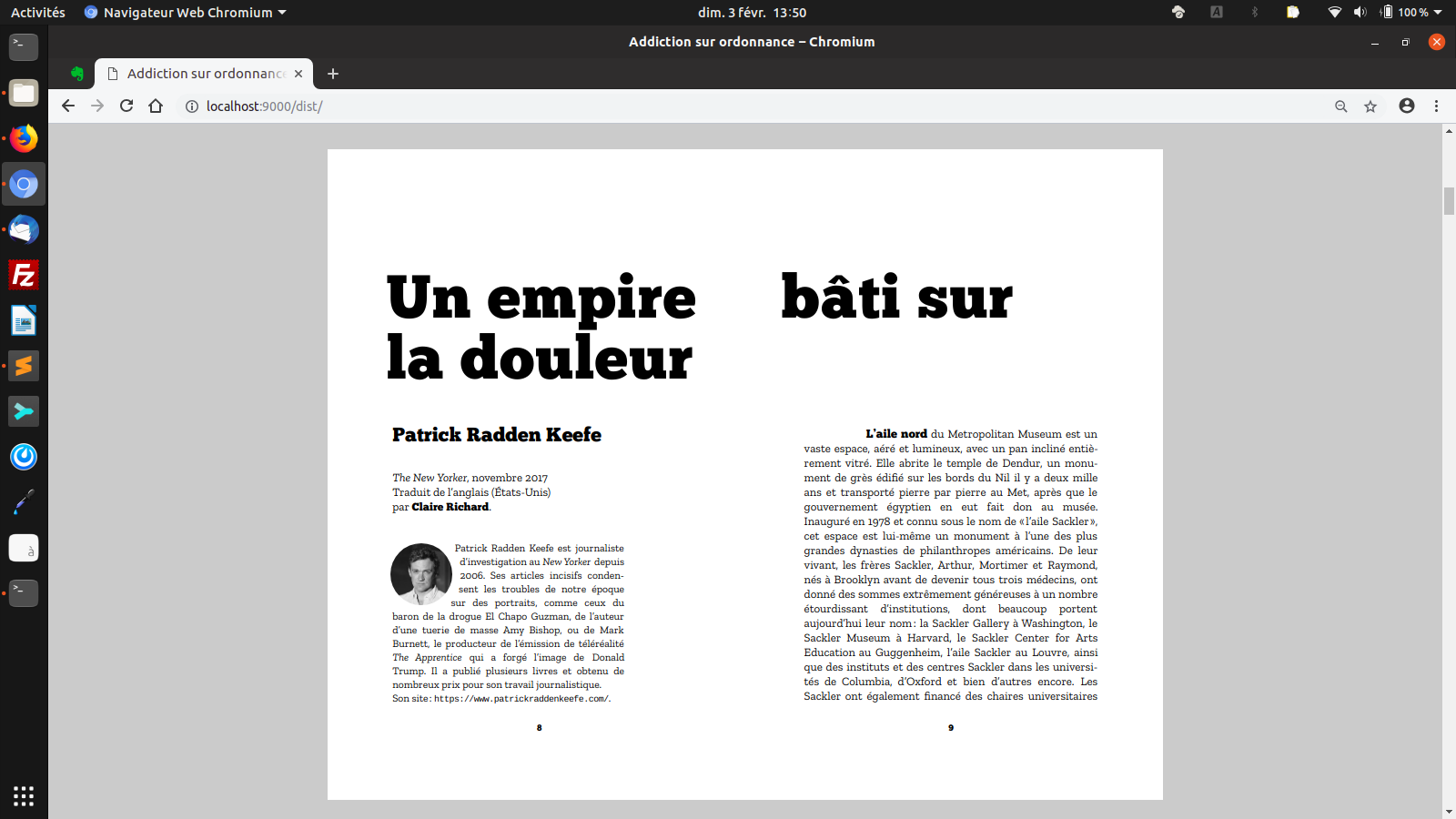
La mise en page telle qu’elle apparaît dans Chromium. Ici une double page de titre avec une gouttière un peu particulière pour tenir compte de la reliure.

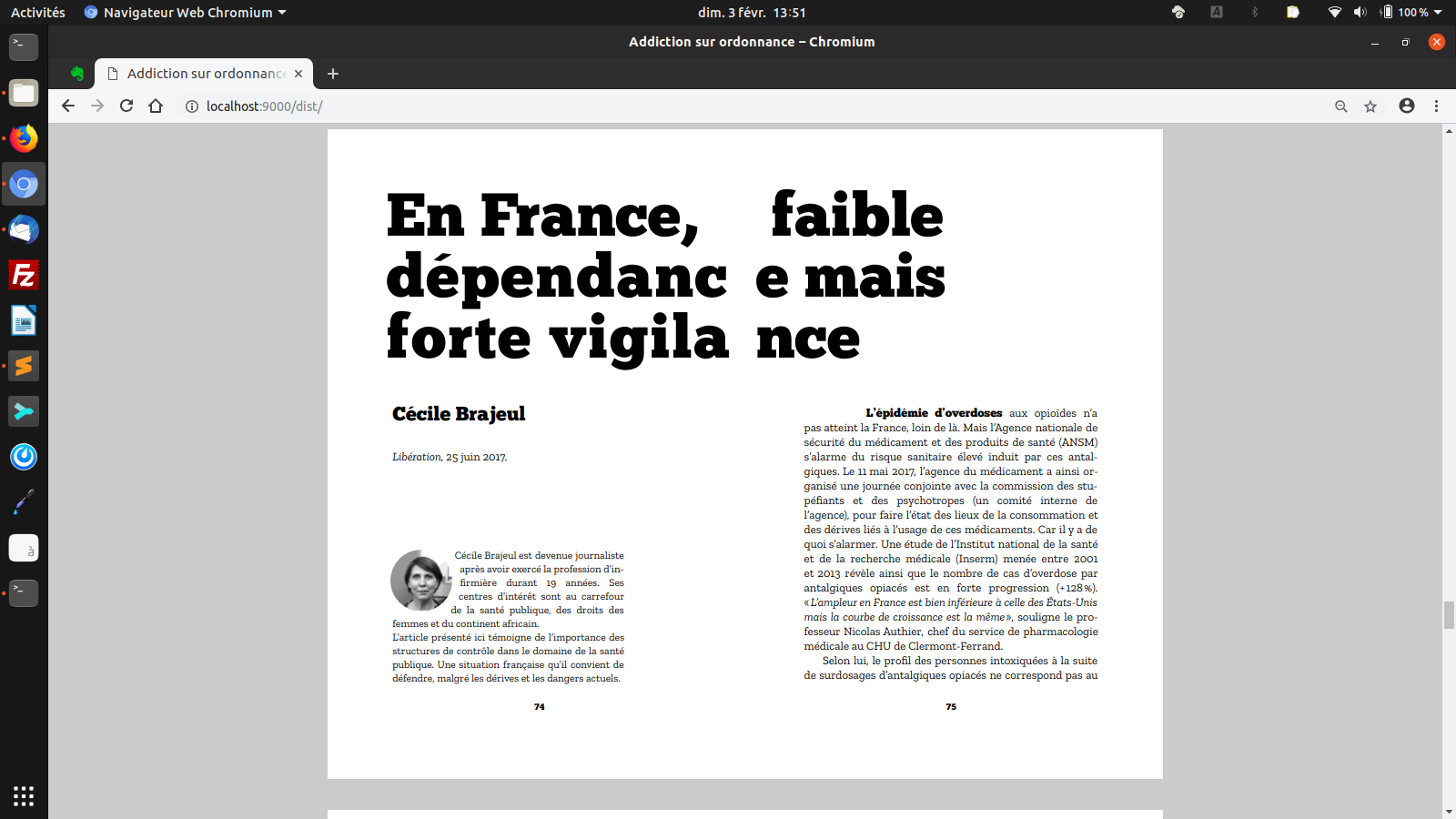
Une autre double page de titre avec sa gouttière un peu particulière pour tenir compte de la reliure.

Une double page dans Chromium.
Encore une double page

les notes, renvoyées à la fin malheureusement,
Concluons
Le livre obtenu n’est donc pas parfait, mais au final, le livre est là ! Il paraît la semaine prochaine (j’éditerai ce post pour ajouter quelques images de l’objet imprimé et façonné, j’espère qu’il est beau). Et comme l’annonce le Colophon : « Il n’est jamais trop tôt pour l’émancipation et nous espérons que nos lecteurs nous pardonneront les quelques limitations typographiques que cela implique pour ce premier volume. Suivre cette collection, ce sera suivre les progrès de cette méthode libre de mise en page. » En attendant, je vous propose de télécharger le spécimen pour jauger le résultat.
Télécharger le Spécimen Addiction sur ordonnance au format PDF.
Personnellement je suis emballé par le procédé et prêt à surmonter ses petits défauts pour continuer. Je reconnais qu’il est un peu prématuré d’envisager de basculer toute la production de la maison dedans, mais pour une collection pilote c’est convaincant. En tant que graphiste, je pense que la pratique des logiciels libres est un plus essentiel sur notre pratique et permet également de développer des marchés bâsés sur la durabilité et la confiance. À faire.
le colophon
Les avantages
- La clarté et la simplicité du html pour ceux qui aiment le balisage sémantique.
- La joie de voir toutes ces belles propriétés CSS dédiées au média paginé fonctionner grâce à l’astuce des développeurs de Paged.js. C’est satisfaisant.
- Le plaisir de naviguer dans des planches de pages et de voir sa composition typographique dans la fenêtre du navigateur, fidèle au PDF obtenu.
- L’emploi d’outils simples comme éditeur de code, pour décrire clairement ce qu’on veut, plutôt que se perdre dans le cliquodrome aux palettes et fenêtres infinies d’options et des sous-options à cliquer de votre logiciel de PAO habituel.
- La libération du livre des solutions de PAO propriétaires bien-sûr.
- La version ePub à portée de quelques éditions mineures et rapides.
- Un fichier source propre et dénué de mise en forme, pérenne et interopérable.
- La possibilité d’ajouter ses petites modifications et modules perso au moyen de Hooks. C’est ça le logiciel libre.
- L’engagement des acteurs et des développeurs pour la cause du livre, et leur proximité.
Les inconvénients
- Des petits soucis d’ergonomie. Par exemple, on ne peut atteindre facilement une page, utiliser le hash dans l’adresse serait bien pratique pour ce faire. En revanche, on peut tout à fait ne compiler qu’une partie du livre, pour gagner du temps, il suffit de commenter les autres sections dans le html.
- Une mise en place un peu lourde si vous n’avez pas un serveur web actif sur votre machine, avec des dépendances. Cela nécessite pour le moment un peu de culture du développement (ne serait-ce que Git), mais l’équipe travaille à simplifier ça.
- Pas de notes de bas de page pour le moment, trop instable et imprévisible, mais l’équipe y travaille. Souhaitons qu’ils surmontent rapidement toutes les difficultés que cela pose. Car c’est loin d’être simple.
- Un manque d’intelligence linguistique (C&J – césure & justification – du français) des outils logiciels, qui n’est pas du tout évident à contourner. Ceci dit, sur certains points, on a déja dépassé InDesign qui est assez crétin sur certains détails.
- Au final, on a bien un PDF, mais il n’est pas encore tout à fait fini : c’est un fichier en RVB qu’il faut penser à convertir en noir ou en CMJN, ce qui demande une version professionnelle d’Acrobat, d’autant plus qu’il faut ajouter ses traits de coupe pour l’imprimeur. Bon après ce n’est pas un drame absolu, et je sais bien que le fichier final passera encore entre les mains de logiciels privateurs chez l’imprimeur, par exemple celui du RIP, donc sachons déjà être content de ce qu’on a.
Mais tout cela est en plein développement et je suppose que cela va beaucoup évoluer dans les mois qui viennent. Un grand bravo pour tout le travail accompli dans pagedjs, et un grand merci aux développeurs pour le soutien dans les moments de doute :-)
Maintenant, on peut feuilleter le livre, imprimé, et le mieux est encore de se procurer un exemplaire !
Addictions sur Ordonnance, la crise des antidouleurs. Patrick Radden keefe – C&F éditions, 16 € – ISBN 978- 2-915825-90-9 – (Collection interventions).

Le livre en volume, et dans toutes les bonnes librairies ;-)



« C’est cette toute dernière solution que j’ai choisi » avec un e, choisi. Si vous avez besoin d’une correctrice… :)
Merci, je corrige et il y en a probablement d’autres, car je n’ai pas trop relu j’avoue.
Oups, pardon, mais à relire, je crois que je c’est mon orthographe que je choisis ;-) Car la phrase est « c’est cette dernière solution que j’ai choisi de tester… » j’ai choisi quoi ? la solution ? non : de tester la solution (infinitif – https://www.question-orthographe.fr/question/choisiechoisi-accord-apres-que/)
D’accord avec toi, Nicolas. Le « truc » de la question « quoi ? » est piégeux, en revanche, il vaut mieux s’en passer. Josette a fait deux pages magnifiques à la fin du PR sur l’accord du p. p. Uniquement des exemples, sinon la métalangue aurait pris toute la place. J’ai lu ton papier. on ne peut pas dire que j’ai tout compris… (ouhlà)
Un léger détail si tu permets: les dépendances dont tu parles sont surtout liés à ma façon de bosser. Tu pourrais tout à fait ajouter le script à un html et partir de là. Le serveur http est effectivement le seul élément obligatoire (d’ailleurs, entre temps, j’ai viré grunt, grâce à l’excellent Thomas Parisot et je tourne avecc npm seulement).
Quand à l’export PDF, nous sommes en train de regarder du côté de Ghostscript pour voir ce qu’il est en possbile d’intégrer, ainsi que de réfléchir à une interface pour rendre tout ceci plus facile.
Le petit Paged.js a tout juste un an :D
Merci!
Super, ce que je veux dire, c’est qu’il faut quand même une culture de développeur pour gérer node, mais en effet, ça va se décanter, je suis confiant ! Merci en tout cas…
Ceci dit, si tu veux que je révise la procédure, c’est possible.
J’ai édité l’article pour être plus précis sur la question, si on a apache actif sur sa machine par exemple, pas besoin de node.
top. merci pour ce compte-rendu d’expérience.
Super intéressant votre retour d’expérience et motivant pour se mettre à tester ! Deux remarques d’imprimeur numérique : nous demandons toujours un PDF sans traits de coupe! Parce que l’imposition dans le RIP impose mieux sans, donc nous passons notre temps a les enlever (: Ensuite, nous travaillons de préférence depuis des PDF normés ( vers une destination Fogra39) mais préférons aussi toujours des bons PDF en RVB plutôt que des séparations CMJN hasardeuses…notre chaîne graphique assurant mieux la séparation vers les CMJN de notre couple presse/papier. Dernière remarque, nous travaillons principalement pour des photographes (micro éditions, zine, etc.) comment ca se passe justement la gestion des images avec cette solution paged.js? Suis curieux de pouvoir mettre en page un zine photo avec ce genre d’outil ! Et pouvoir sortir de la suite Adobe…
Merci pour votre commentaire, ahah, c’est amusant cette histoire de traits de coupe. En effet, en numérique on est bien en RVB, ça je le savais, mais j’ignorais que vous aviez à retirer les traits de coupe. Ce livre a été imprimé en offset, c’est aussi ce qui rend les choses intéressantes. Pour les images en RVB, je suppose que si le profil est embarqué cela ne pose pas de souci. Pour ma part, les images en gris sont bien sorties, en haute def.
Merci à André Sintzoff pour le décoquillage !