Il y a presque deux ans, je présentais ici le making-of d’une collection chez C&F éditions (la collections interventions, qui s’est étoffée depuis) produite avec des logiciels libres et en particulier dans un navigateur web, au moyen du code html, des feuilles de style css et du palliatif (ou polyfill) Paged.js qui supplée au manque de support par les navigateurs web de la spécification du W3C pour les CSS destinées aux médias paginés.
Dans ce post (long), je voudrais raconter la suite des événements et faire le point sur l’état de mes travaux.

Le procédé utilisé pour notre premier livre présentait des limites, que j’expliquais alors, surtout en ce qui concerne le flux de texte (le gris typographique, étant donné l’algorithme assez sommaire de justification et les césures souvent inopinées) ; mais sincèrement, on croise parfois des résultats équivalents, sinon pires, en librairie, dès lors que les logiciels PAO n’ont pas été correctement paramétrés. À noter aussi, l’absence de notes de bas de page, pas encore au point, mais qui finalement nous a permis de nous réconcilier un peu avec les notes de fin de section. Ces notes de fin demandent un peu plus de travail au lecteur, mais permettent d’avoir des pages finalement plus harmonieuses. Disons que c’est un arbitrage que nous n’aurions pas fait spontanément, mais que nous avons accepté.
Ce procédé est également tout à fait intéressant à plusieurs égards : d’abord il s’articule à une pratique que nous avons, de recourir massivement aux feuilles de style, toujours nommées de manière sémantique c’est à dire en référence à la motivation et non aux attributs visuels du texte ; ensuite, il nous donne une forme de contrôle, d’ouverture et de disponibilité en exposant le code source du livre dans deux langages que nous aimons pour leur lisibilité : html et css, il s’approche aussi de la publication epub qui est pour nous dans la continuité du livre imprimé, il nous permet aussi de travailler à plusieurs à distance avec git, sans se préoccuper des installations, des licences de logiciels de PAO, et ouvrant le chantier à des non-spécialistes de l’usine à gaz Adobe (comme mon collègue Hervé Le Crosnier ;-). Et puis enfin, il faut reconnaître que c’est irrésistible d’inventorier, de reconstituer et donc de repenser pas-à-pas ses besoins. C’est une bonne pratique de designer, qui permet d’évaluer chaque caractéristique, de prioriser, bref, de ne rien employer qui ne soit nécessaire, sous prétexte que ce serait disponible dans l’interface d’un logiciel.
Je pensais à la fin de ce chantier avoir fait le tour des difficultés principales et pouvoir faire des livres ainsi. C’était bien-sûr mettre de côté la complexité et l’exigence du média paginé, car il ne s’agissait pour le moment que d’un livre de texte simple. Ce qui est vrai pour une collection ne l’est pas pour toutes. La première ligne de crête franchie, je découvrais seulement de là-haut la vraie chaîne de montagnes que nous avions devant nous :-). Mais pour aborder tout cela il faut parler plus spécifiquement d’un autre projet. il s’agit d’avantage d’un manuel d’apprentissage, avec un chapitrage, mais aussi de nombreux éléments accompagnant le texte (figures, définitions, exemples, encadrés, listes etc.) qui viennent le compléter et qu’il est plus difficile de traiter simplement dans le flux du texte principal. Bref, nous voici repartis. Commençons par parler un peu de la manière dont les choses se font.
Des gens, des fichiers et des livres
Un des gros problèmes de la fabrication numérique de livres est l’articulation des différents moments et acteurs éditoriaux avec les logiciels et formats de fichiers. Avec l’auteur, on échange souvent des fichiers de traitement de texte (dans le meilleur des cas, on travaille en mode révision avec l’auteur, dans son traitement de texte, puis on accepte les révisions consensuelles, on y applique des styles, après avoir soigneusement nettoyé tous les enrichissements de texte plus ou moins inopinés). Cet échange ne se fait donc pas encore avec la mise en forme que permet le fichier de PAO, qui est quant à lui beaucoup plus difficile à échanger (pour des raisons de licence, de connaissance, et aussi de ressources à associer, comme les polices, etc). À Chaque étape, on peut avoir des besoins de correction, et la correction du texte peut impacter sa mise en forme à son tour. Une fois le fichier importé et composé dans un logiciel de PAO, on passe par une impression ou un PDF pour corriger des épreuves, mais au moment de décliner sur un autre format, on se trouve confronté au fait que la dernière version, corrigée, est devenue prisonnière du fichier PAO, et que la version de départ, dans le traitement de texte, est devenue obsolète.
Pour éviter ces problèmes, certains ont réfléchi à des flux de production à format pivot (single source). J’ai pu découvrir et pratiquer le flux Métopes de la Maison de la recherche en sciences humaines de l’université de Caen, qui s’articule autour du format pivot XML en TEI, avec des ramifications propriétaires pour coller aux usages de l’industrie : Word de Microsoft pour l’écriture et le stylage, Adobe InDesign pour la mise en page imprimée. Métopes, qui se constitue d’un ensemble de scripts et d’outils, insère entre les deux un fichier XML, qui permet de structurer et de créer ce qu’on appelle une expression, une source unique, interopérable pour toutes les manifestations (html, epub, imprimé, pdf, daisy, etc.). Ce flux apporte des possibilités très inspirantes, et son lot de contraintes : rigueur absolue du XML, double report d’une erreur découverte tardivement, difficulté à s’accommoder de besoins ad-hoc, et la nécessité d’une – relativement solide – formation. De toute manière, on échange pas de fichier XML avec l’auteur, on échange toujours du traitement de texte et des épreuves, et on se charge de reporter d’éventuelles corrections tardives à la fois en PAO et dans le XML.
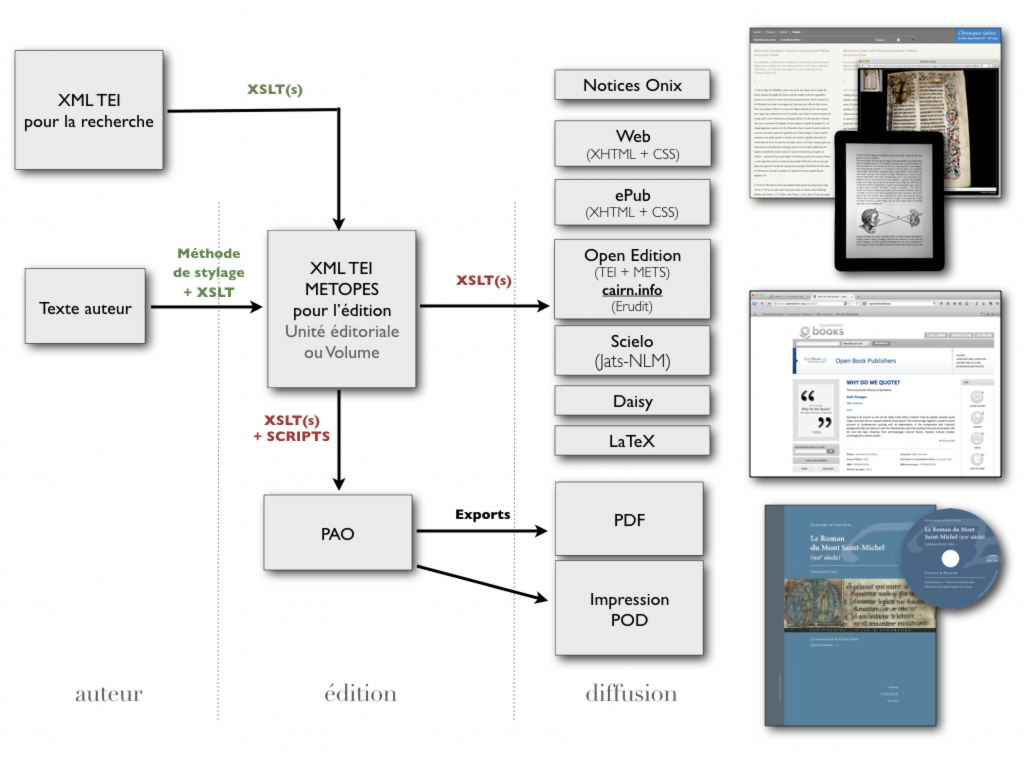
XML est très intéressant, mais s’articule avec des outils d’écriture (traitement de texte, notamment). Or on ne peut faire abstraction de l’aspiration à sortir des traitements de texte, de la multiplication d’outils alternatifs. Inspiré par le html et aussi par les langages de balisage léger, comme Markdown (qui permet de constituer une structure simple de html standard sans avoir à subir visuellement le code, et a été créé pour faciliter l’écriture, ce qu’on appelle le flow, d’un blogueur), je me suis demandé si on ne pourrait pas utiliser le flux html + css pour faire le livre, mais également, pour proposer des modalités d’écriture et d’inclusion de l’auteur et du designer dans un processus éditorial.
Il ne s’agit pas d’automatiser la mise en page, c’est un point sur lequel j’insiste, car les flux html + css ont tendance à faire fantasmer certains éditeurs qui se disent qu’ils vont pouvoir automatiser d’avantage, voire se passer de compositeur. À eux je souhaite bonne chance, surtout s’ils sont un minimum exigeants sur la qualité de composition. Non, c’est une autre manière de composer, tout comme markdown offre une autre manière d’écrire que Word, l’idée restant de fournir au compositeur une palette suffisamment complète pour lui permettre de bien travailler. Les gens, leurs savoir-faire ont toute leur place, et il s’agit plutôt de leur proposer une palette alternative suffisamment complète pour qu’ils et elles puissent s’exprimer.
Ici, il s’agit de permettre une collaboration plus serrée entre l’auteur et le designer-compositeur, en temps réel, avec autant d’itérations que souhaité. C’est utile pour un projet ou le designer intervient très tôt, ou bien quand l’auteur aime la contrainte de s’adapter à une forme finale pour écrire. Ce qui est fréquent par exemple dans la presse, avec des outils propriétaires comme par exemple inCopy d’Adobe, qui permet aux rédacteurs de voir la place assignée à leur copie dans la maquette, et l’état d’avancement des pages.
Bonjour Asciidoc
Mais si Markdown est pratique pour l’écriture de manuscrits simples, il est volontairement et à bon escient limité, et difficile à étendre. Cela signifie qu’il prend en charge des niveaux de titres, paragraphes, citations, listes, et en gros c’est tout. Pas de quoi ajouter des encadrés, des définitions, des exemples et autres éléments documentaires. Mon point de vue : gardons simples les choses simples. Il existe un langage du même type mais mieux adapté à la réalisation de documents structurés pour la documentation et les manuels : Asciidoc. Asciidoc n’est pas une nouveauté, c’est même plutôt un vieux de la vieille qui a été créé en 2002 (!). Il permet d’écrire en balisage léger et d’obtenir par compilation du html (il faut une petite extension pour avoir un html moderne et plus sémantique, car par défaut, Asciidoc produit un html un peu old school et surchargé). Avec Asciidoc, à nous les encadrés, les définitions, les exemples, les tableaux, et une infinité d’autres possibilités, puisqu’il est ouvert à nos propres catégories. Il s’avère donc à la fois beaucoup plus complet (avec l’inconvénient de demander un apprentissage, du coup), et plus extensible, permettant de créer des blocs personnalisés avec une syntaxe très simple.
Attention, ce n’est pas une entrée en religion que je propose ici, simplement Asciidoc est une forme qui me semble plus adaptée à notre type de publication. Le procédé décrit après peut tout à fait fonctionner avec d’autres langages, html, markdown ou autres…

J’ai donc commencé par tester si le contenu du manuel que j’avais en projet, et dont l’auteur, Wendy Mackay souhaite avancer l’écriture avec moi, pouvait fonctionner en Asciidoc. Il se trouve que ça convenait vraiment bien. Je n’entre pas dans le détail ici, j’y reviendrai peut-être. L’important à comprendre est que l’auteur peut structurer sémantiquement son manuscrit de manière assez fine, sans avoir à se préoccuper de la mise en forme. Avec une petite astuce, à chaque sauvegarde, on compile le html et si on veut, on le prévisualise dans un navigateur web, avec par exemple un feuille de style css paginée. On s’y croirait.
Le retour des styles
Pas tout à fait. Le stylage ne peut être entièrement automatique, même si une feuille de style assez élaborée a été préparée en amont, il y a parfois des arbitrages à faire, des petites adaptations locales, en particulier avec l’imprimé, car la page, et la double-page, avec leurs limites strictes en hauteur et largeur, leurs marges, imposent leur format, au contraire du scroll infini et de l’élasticité de la page web. Comment donc le compositeur peut-il introduire des changements locaux nécessaires au « calage » a posteriori de sa double page, sans venir mettre sa pagaille dans le manuscrit ou le code source du texte lui-même (en y ajoutant ou déplaçant des éléments, non pas selon les critères logiques, mais selon les critères esthétiques et de plus contingents liés au format précis de sortie).
J’ai pour cela introduit une troisième source. On se retrouve avec trois fichiers : le manuscrit balisé sémantiquement au moyen de Asciidoc, donc, obéissant à sa propre structure, en sections, paragraphes, d’une part, la feuille de style CSS générale d’autre part, qui s’occupe de construire le livre, et une autre CSS liée à la sortie dans un certain format qui permet de cibler certains éléments et de leur ajouter un ajustement local a posteriori.
Le problème est qu’il faut à cette feuille de style pouvoir cibler tous les éléments. Certains sont faciles à attraper au moyen des sélecteurs et en particulier des pseudo-classes :nth… d’autres sont plus difficiles, parce que la structure du code html est profondément modifiée à la volée par Paged.js lorsqu’il crée des pages, découpe le contenu, lui donne de nouveaux contenants…
J’ai donc profité des « hooks » que permet Paged.js, un système astucieux conçu par le brillant développeur Fred Chasen, créateur de Paged.js, qui permet d’insérer ses propres instructions à différents moments dans la chronologie de son traitement du contenu, de son découpage, de sa mise en forme. Pour commencer, afin d’ajouter une petite routine qui repère et identifie certains éléments (figure 1, 2, 3… exemple 1, 2, 3, définition 1, etc.), ainsi que les sections et sous-sections. C’est encore un peu ad-hoc mais on peut l’imaginer personnalisable. Une fois cet étiquetage fait, il est possible d’attraper un élément et de changer ses attributs, dans une feuille de style séparée, nommée tweaks, car réservée aux petits ajustements localisés et circonstanciels.
(récréation) Reload-in-place
Pause : ma première petite fierté est une broutille qui change la vie. Comme vous le savez, lorsqu’on fait une modification de texte ou de style, il faut recharger une page web dans le navigateur pour voir les changements. Avec une page web ordinaire, le navigateur recharge la page, puis se repositionne là où il était dans la page si on avait scrollé. Mais dans le cas d’un livre paginé, il ne le fait pas et se positionne en haut, page 1. C’est embêtant, lorsqu’on corrige la page 128, de devoir sans cesse recharger, attendre puis aller la retrouver à la main, cette page 128, pour voir si la correction est bien apparue.
J’ai donc ajouté une petite extension à Paged.js qui permet après le rechargement, de rejoindre automatiquement, et le plus vite possible la page 128 (ou une autre, sans supplément de prix ;-), sans attendre que la compilation totale du livre soit effectuée. Je vous l’offre, car je la considère indispensable pour mettre au point un livre. On recharge et l’affichage revient là où on en était, sans attendre que le livre entier soit compilé. Indispensable (fin de la pause).
Traits de coupe, débord et double page
Une nouveauté du dernier titre de la collection interventions, c’étaient des intercalaires illustrés en double page entre les parties du livre. J’ai pu bénéficier du travail de Julie Blanc et Julien Taquet sur l’interface de Paged.js qui proposent de faire apparaître une zone de débord autour de la page, avec des traits de coupe.
Pour mettre une image en double page, j’ai en réalité positionné deux grands blocs, un sur chaque page, débordant dans la zone de coupe, et importé deux fois mon illustration. La feuille de style calcule, en fonction de la présence de ce type de bloc sur la page de gauche ou de droite, le décalage d’image qui permet de positionner les deux morceaux bord à bord. Vive les css calc() et les variables.

Mais la présence de cette zone de débord, avec les traits de coupe directement dans Paged.js (et non plus ajoutés a posteriori au PDF) permet d’envisager et de réaliser toutes sortes de nouvelles disposition qui sortent de l’empagement, et donc du livre de texte pur et dur.
Encadrés
La deuxième chose nouvelle dont j’avais besoin pour ce projet, c’étaient des blocs qui glissent hors du texte, dans la marge, mais avec des comportements parfois différents.
Certains, comme des notes marginales doivent suivre le paragraphe auquel elles sont ancrées. C’est le cas ici aussi pour les légendes de figures. Pour ces éléments, j’ai opté pour un positionnement absolu, relatif à leur parent (pour la hauteur) et un comportement légèrement différent sur les pages de gauche ou de droite, avec le même résultat, ils sont dans la marge extérieure (le grand fond).
Mais d’autres sont un peu différents. On peut imaginer des encadrés, qui se positionnent de manière absolue dans la marge, par rapport à la page, et non à leur point d’insertion dans le manuscrit. Mais il peuvent aussi être plusieurs, et dans ce cas, il ne faut pas qu’ils se superposent mais bien qu’ils se juxtaposent. J’ai opté pour la création d’un conteneur pour eux dans la zone de marge de Paged.js elle-même, un hook les retire du flux de texte et les déplacer, un par un, dans cette zone.
C’est un troisième type d’encadré qui pose le plus de difficulté finalement, les grands encadrés insérés dans le texte lui-même. En effet, ces grands encadrés trouvent une place précise dans le manuscrit, mais dans une page, ou double-page, ça ne se passe pas comme ça…

Flottements
Tant qu’un livre ne contient qu’un texte en effet, tout se passe bien, mais certains éléments (textuels ou iconographiques) ont un statut particulier qui peut les détacher du texte. Il peut s’agir de notes par exemple, dont on voit bien qu’elles sont un renvoi au sein du texte principal vers un petit fragment de texte qui en est précisément extrait pour être renvoyé à la fin de l’ouvrage, de la section, ou bien, et c’est là que ça devient intéressant, à une région particulière de la page : en bas pour les notes de bas de page, ou dans une marge pour des notes marginales, des gloses…
Ce n’est pas tout : il y a aussi des figures, tableaux et certains encadrés qui figurent dans le texte mais ne tombent d’ailleurs pas toujours bien, une fois placés dans l’espace borné de la page. Par exemple, un encadré peut arriver à cheval sur deux pages. Dans ce cas, il faut la sortir du texte, et le faire « nager » jusqu’au haut de la page suivante par exemple, tout en faisant passer une portion de texte correspondante, sous l’encadré, pour la rattacher au texte la précédent et combler le vide. Cela se fait en PAO au moyen des blocs ancrés, et avec LaTeX des éléments flottants (floats). En CSS, la chose est aussi prévue depuis 2015, avec des possibilités très intéressantes, mais pas du tout implémentées pour le moment. Paged.js pourrait s’y pencher prochainement. En attendant, pouvions-nous y palier au moyen d’un de ces Hooks ?

Encore une fois, j’ai pu bénéficier du travail de de Julie Blanc qui s’intéresse à la question depuis un moment et avait déjà publié un article complet et même un petit script pour pousser les encadrés en haut de page suivante dans une de leurs précédentes expérience. J’ai de mon côté travaillé dessus pour obtenir deux modifications importantes à mes yeux : d’une part plusieurs possibilités (quatre en tout, pour atteindre les quatre extrémités de la double page, décrites ainsi : la même page en pied, et en tête, la page suivante en pied et en tête – on ne peut pas revenir à la page précédente, déjà composée par le script, et d’autre part, une manière de le faire correspondant à mon approche, en effet je ne pouvais me permettre de déclencher cette migration par l’ajout d’une classe dans le html. Laissez-moi vous expliquer pourquoi.

Les scripts proposés par les talentueux développeurs de Paged.js Julie Blanc et Julien Taquet s’appuient souvent sur une classe qui déclenche tel ou tel comportement, c’est simple, efficace… mais c’était précisément en contradiction avec ma ligne directrice : essayer de ne pas avoir à changer l’ordre des éléments dans le texte / code source, ni d’ajouter de classe motivée par le graphisme, de classe qui ne soit pas sémantiquement justifiée dans le manuscrit source. Ce source, qui est en Asciidoc et même pas en html, dans un format d’écriture, donc, que j’essaie de réserver à l’auteur.
La ligne du parti
C’est bien une opération intentionnelle du compositeur qui permet de sortir un bloc du flux de texte et de choisir sa destination. Une decision au vu de la double page, d’en améliorer l’aspect. J’ai donc proposé une css dévolue à cet usage. Le designer dispose ainsi de deux feuilles de style : une pour la composition générale, et donc « automatique », applicable à l’ensemble du manuscrit, et cette autre, nommée tweaks.css pour procéder à des ajustements au vu du résultat une fois composé. Même si on peut définir des règles automatiques pour ne pas couper une figure, la décision sur l’emplacement d’un bloc en « page float » se fait à ce moment là, a posteriori. Tout comme peuvent l’être d’autres détails et petits ajustements qui permettront de gagner deux lignes par ici, aligner un élément sur un autre, ou à l’inverse de le pousser un peu plus loin. L’idée est de bien retrouver les deux temps de la composition : celui que le designer consacre à l’élaboration de son gabarit et de ses feuilles de style, et qui vont accueillir le contenu dans l’espace de la double page, et celui où il décide, au vu du rendu de telle ou telle page, de procéder à quelques aménagements. On peut tout à fait imaginer que l’auteur fait de même de son côté, en modifiant un peu son manuscrit en fonction de l’aperçu qu’il obtient de son texte une fois mis en page (par exemple pour équilibrer la longueur de deux définitions, pour parce qu’une légende prend trop de place, etc.) En effet, certains auteurs écrivent avec des contraintes de forme, soit parce qu’ils aiment ça et que ça les stimule, d’écrire pour tel ou tel cadre, soit parce que leur media les y contraint franchement (les rédacteurs de presse se reconnaîtront). Nous avons ces quatre temps actifs de publication :
- le temps de la rédaction (et de l’illustration)
- le temps de la maquette
- la retouche par le rédacteur
- la retouche par le compositeur

Chaque temps s’effectue autant que possible dans le fichier le plus adapté, ce qui évite à un des acteurs d’avoir à trouver des modifications inopinées, venues d’un tiers, et une syntaxe qui ne lui appartiennent pas dans son fichier. Cela simplifie en outre la gestion de versions de fichier, puisque cela réduit les risques de conflit de version (les fichiers sont synchronisés entre auteur et designer via NextCloud à ce stade). On peut imaginer un éditeur de fichiers qui donne à chacun un espace de travail sur ses fichiers et un aperçu commun du résultat.

Tout ça est bien en théorie, en pratique c’est plus difficile. D’abord le fait d’utiliser une compilation en html5s pour le html rendu à partir d’Asciidoc fait perdre les identifiants. Asciidoc étiquetait de manière assez utopique, tous les éléments au moyen d’un id numérique. Utopique puisque chaque modification (ajout d’un paragraphe par exemple) modifiait l’ensemble des numéros (Paged.js fait de même). Mais pour que la css tweaks du designer fonctionne, il faut que celui-ci puisse désigner (sélectionner en terminologie css) de manière fiable et pérenne l’élément visé.
Attrape-moi si tu peux
Une syntaxe permet en théorie de se passer d’identifiants, les sélécteurs de type nth-child qui combinés avec des chiffres et lettres, permettent en théorie de cibler des éléments sans classe et sans nom
par exemple l’avant dernier paragraphe de la troisieme section s’écrirait :
section:nth-child(3) > p:nth-last-child(2) {
jolie: css;
}
ou les lignes paires du deuxième tableau tableau à partir de la 6e :
table:nth-child(2) tr:nth-child(2n+6) {
jolie: css;
}
Cela convient dans certains cas (bien que peu pérenne, un changement en amont pouvant bousculer ce comptage) et ça s’applique assez bien au DOM du code source du manuscrit. Mais c’est plus difficile avec le DOM paginé une fois rendu par Paged.js. Un exemple : Paged.js coupe les sections au fil des pages, et c’est bien normal, mais, il les réécrit au sein de chaque page. Ces sections se retrouvent donc multipliées dans le DOM, autant de fois qu’elles parcourent de pages. Ainsi un document d’une section sur six pages contiendra six pages avec six sections enfant. ça complique vraiment les choses pour compter au vu du résultat, et ça bouge pas mal.
J’ai donc commencé par créer une petite routine en Hook qui attribue un ID correspondant à la numérotation des éléments, figure 1, figure 2,… tableau 1, tableau 2,… exemple 1, exemple 2. Les sections aussi sont identifiées en fonction du nom de leur titre (h2) et de leur numéro d’ordre. Ainsi il devient possible de cibler une figure, pour lui assigner une propriété page-float, dans l’idéal. Car comme cela n’existe pas encore vraiment, j’ai besoin d’une classe pour déclencher le script. Ça donnerait donc en théorie :
#image-block_5 {
.page-float-next-top;
/* on ne peut pas faire ça */
}
Mais on ne peut pas inclure une classe CSS dans un ensemble de propriétés comme on peut le faire en LESS ou SASS par exemple, ce qui serait pratique. De toute manière ce que fait LESS dans ce cas est simplement d’aller chercher les propriétés et leurs valeurs de la classe indiquée et de les rapatrier dans l’ensemble qui les appelle. Il n’étiquette pas l’élément du DOM avec ladite classe. Or c’est ce qu’il me faudrait : partir d’une css pour ajouter une classe dans le DOM.
J’ai donc (avec l’aide de Julien Taquet, parce que tout seul j’aurais eu du mal) écrit un petit script qui s’exécute juste avant Paged.js et qui va ajouter ces classes dans le DOM en fonction de ce qui est déclaré dans tweaks.css pour que Paged.js (et son hook consacré aux page-floats) les repèrent et opèrent le substitut de page-float. Pour cela, et à titre de preuve de concept, j’ai donc carrément créé une propriété css à moi (propriétaire donc), qui serait à retravailler sur le modèle du working draft du W3C, mais qui très temporairement s’appelle –taffin-page-float, et qui peut prendre quatre valeurs : same-top, same-bottom, next-top, next-bottom. ce qui donne dans tweaks.css
#image-block_5 {
--taffin-page-float: next-top;
}
et qui permet à la fois d’ajouter la classe dans le DOM, sans intervenir sur le manuscrit, puis de déclencher le comportement du hook réservé à ce type de page float (position en premier dans le contenu de la page suivante : en gros, les blocs qui vont en haut sont déplacés par le script, ceux qui vont en bas sont positionnés de manière absolue). Ouf. Ça parait un peu compliqué comme ça, mais cela suit la logique proposée, et ça marche, modulo une bonne gestion de la chronologie des événements par le script. Je ne remercierai jamais assez Julien Taquet pour son aide et sa fine connaissance de Paged.js.

Sur cette base et quelques bugs plus tard, j’ai pu produire mon chapitre de manuel, avec grosso modo tous les petits raffinements nécessaires. Je voulais documenter un peu l’approche, c’est pour cela que j’ai écrit ce post.

Prochaines étapes
Les codes sources sont ouverts et je peux les proposer à la communauté, je les ai déjà transmis à mes complices à qui je suis tant redevable, comme je l’ai fait pour le Reload-in-place si utile au quotidien, même si je voudrais encore prendre le temps de finaliser des choses avant, et notamment changer le fonctionnement (et le nom) de la propriété propriétaire :-)
Je voudrais aussi confronter ce fonctionnement à d’avantage de chapitres / modèles, bref, prendre un peu de temps, car c’est ainsi que les choses se consolident, se complexifient, puis se simplifient. Pas si évident de contribuer utilement à un projet libre, c’est un investissement important et le syndrome de l’imposteur guette.
Mais enfin, l’idée est maintenant de se glisser dans un flux, un éditeur un peu plus intégré, soit en s’appuyant comme je le fais actuellement sur une plateforme, comme VSCode, soit de préférence en utilisant le navigateur web comme environnement de travail. Là encore je ne suis pas le seul à y penser, il y a par exemple l’astucieux printcss.live de Andreas Zettl, Stolon de Raphaël Bastide, ou même Editoria. Il serait possible de partir d’une base et de la modifier à titre de contribution, quand la licence le permet. Car tout cela ajoute un autre niveau de complexité (gestion des fichiers et des droits essentiellement) et j’aurai besoin d’aide. Voilà voilà, pour le moment, désolé pour le long post. Questions ou commentaires bienvenus !

Wonderful. We are obviously on the same page (so to speak).
Thanks a lot, indeed ! Even if we may remain marginal…
Très intéressant et bravo pour ce travail. Merci à Marin Schaffner qui m’a indiqué ce billet que je viens de repartager dans le groupe @creation_diffusion_et_outils_numeriques_libres sur Mobilizon.
Merci à vous (et désolé pour le délai)
Looks wonderful. Could you make the source available on GitHub?
Thanks. Part of it is already on gitLab -> https://gitlab.com/nicolastaf/pagedjs-reload-in-place the rest will come soon, needs a bit polishing first…