Tiens, j’ai reçu un courrier d’un certain Franz Kafka. Une petite enveloppe contenant des dessins découpés grossièrement. Presque typographiques, non ? J’ai l’impression qu’ils racontent aussi une histoire… Encore faudrait-il les mettre en suite.
Si vous voulez en savoir plus, c’est en bas de ce post…
Dessins de Franz Kafka issus d’un carnet, circa 1901-7. Credit : הספרייה הלאומית, ארכיון מכס ברוד The National Library of Israel. Max Brod Archive. Photos by Ardon Bar Hama. (Archive en ligne).
Alain Rey, mort le 28 octobre 2020 à Paris. Ce texte est un hommage, publié dans l’ouvrage Salut Alain !, édité par Maya Lavault pour les éditions Le Robert (parution en octobre 2021). Il a été corrigé par Danièle Morvan à qui je le dédicace évidemment, et pleinement.
Il a fallu ressortir du matériel d’époque pour capturer un ancien entretien stocké sur cassette mini DV…
Le-vingt-et-unième siècle était bien entamé quand le lexicographe tira sa révérence. La nouvelle inattendue arrêta le flot de la radio dans beaucoup d’oreilles, car il comptait, il avait progressivement donné une voix et une figure aux épais ouvrages que chacun imagine complets comme ils semblent gros, éternels comme ils semblent désincarnés. Les dictionnaires. Personne n’envisageait la finesse des édifices ni la fragilité de leur auteur. Il faut dire que les médias savent bien maquiller la modestie ou le temps de travail.
Le jour de ses funérailles, il faisait doux au soleil et franchement frais à l’ombre, comme souvent en automne. Les arbres se découpaient haut, en ombrelles clairsemées au-dessus des allées du cimetière.
Devant le bâtiment de pierre claire, ils seraient deux, une femme et un homme, en avance probablement, regardant leurs pieds, pas bien sûrs d’être au bon endroit au bon moment, mais n’ayant pas fait les quelques pas qui les séparent l’un de l’autre, pour vérifier les choses.
La typote aurait le regard lointain comme ses pensées. Elle aurait été surprise par l’annonce, comme tout le monde. Le bâtisseur de monuments s’imprègne de permanence – mais qui a donc décidé que les dictionnaires étaient des monuments, et quand ? Ces objets pourtant dits usuels, son ami lexicographe lui affirmait bien qu’on ne les use pas assez, les jours où il débarquait chez elle avec de gros sacs, désherbant sans ménagement l’étagère à dictionnaires au-dessus du bureau, pour y placer son travail de l’année, avec un sourire de soulagement. En tout cas on ne les use certainement pas en les lisant complètement, on les conserve bien trop longtemps, car ils ne se bonifient pas forcément avec l’âge, et puis ce ne sont pas des talismans.
À cet instant, elle se rappellerait son père typographe, ce qu’il lui avait appris, dans l’atelier enfumé par les gauloises : que depuis longtemps, les humains vivent le nez en l’air dans des nuages d’idées, qu’ils ne pensent, vivent, respirent que dans les mots et les chiffres. Du registre d’état civil au registre d’état civil, b.a.-ba, apprentissage de la lecture, bail ou acte de propriété, pointage de leur temps en échange de la monnaie, imprimée, auprès de personnes morales inscrites au registre du commerce, leur réel de chair et de sang se soumettant au signifié. C’était devenu son travail, à elle aussi : agencer les formes invisibles, puisque tellement lisibles, de la typographie.
Personne ne le voyait, ce travail, c’était un peu comme la couture des doublures, qu’on ne perçoit que quand elles gênent. Et elle savait fort bien ne pas gêner. Arranger les mots sur la page, organiser, composer en toute discrétion. Elle servait aussi fidèlement que possible, sans ajouter de bruit, auteurs, éditeurs, institutions. Au début, elle avait eu du mal dans le monde viril des typographes, qui lui avaient accordé son féminin avec condescendance. Puis l’informatique l’avait aidée, autant à travailler seule, qu’à exister. Elle aimait son travail de composition, et par-dessus tout le fait de préparer, de ménager la circulation du regard à venir des lecteurs. Glisser par anticipation du plaisir pour eux, là où ils n’avaient pas de raison spéciale d’en éprouver.
La typote, éprise de correction, admirait depuis toujours le travail du lexicographe, qu’elle prenait au pied de la lettre. Elle vivait un dictionnaire ouvert sur la table, et y avait même travaillé une fois. Le lexicographe lui en avait rendu une certaine estime, lui qui s’était usé les yeux dans les volumes de ses prédécesseurs avait bien remarqué que certains semblaient plus corrosifs à l’usage, d’autres plus doux. Un jour, il l’avait appelée afin de lui demander si elle pouvait essayer de loger, dans un de ses dictionnaires en projet, autant de mots que possible, sans ruiner son éditeur en achat de papier, et sans ruiner la vue des lecteurs. Elle avait fait des miracles, juste pour lui montrer de quel bois elle pouvait se chauffer. Et lui, il avait ouvert les portes de sa fabrique, présenté sa complice, son épouse : ensemble ils lui avaient dévoilé, un peu, comment on travaille, la pêche aux mots, dans la presse ou une bibliothèque emplie de raretés, la nomenclature, la perception des changements, des glissements. Lire, écouter, parler, comprendre, écrire, refaire le monde, et recommencer, patiemment, l’articulation d’un véritable texte, que l’on « consultera » sans le lire. Modestement, comme ceux qui ne se rendent pas compte que c’est un Himalaya qu’ils ont gravi hier, et recommencent demain. Une amitié était née dans les signes et le papier. Tous deux lui parlaient comme si elle comprenait, mais elle savait que sa connaissance de typote était infiniment moins vaste. Dans le même bac à sable, mais chacun son jeu.
Tout ça, c’était avant les omni-écrans, les tactiles, quand les usuels imprimés avaient encore un usage. Elle n’imaginait pas encore comment les choses allaient se faire sans lui, sans ses lumières. Comment le langage fonctionnerait encore. Elle n’allait probablement pas se retrouver au chômage, il y aurait du travail. Mais quelque chose changeait, elle le sentait. Les dictionnaires avaient besoin d’auteur, de hauteur. Ce n’étaient pas de simples registres, ni des bases de données. Comme la typographie le lui avait appris, il leur fallait l’humanisme, l’humanité. Elle n’avait jamais pensé la fin du dictionnaire possible, et pourtant la couverture du volume, aussi épais soit-il, se serait bel et bien refermée, la laissant comme orpheline.
Elle lèverait alors les yeux, accommodant enfin sur ce qui l’entoure. Un costume approcherait en lui tendant la manche. Elle reconnaîtrait, sans que ce soit instantané, le marchand. Ce marchand qui lui avait proposé du travail au changement de siècle, elle n’avait pas bien compris son affaire. Pourtant, il avait essayé de lui expliquer comment il allait faire sa fortune d’une idée neuve et implacable. Un monde nouveau de purs signes recouvrait parfaitement le monde réel et l’ancien monde de papier. Il était numérique, évanescent et connecté. Des naïfs l’avaient nommé « virtuel » ; pour le marchand ce monde n’était pas plus virtuel que le monde des idées cher aux philosophes, ou celui des transactions accélérées de la finance. Il était juste en construction. Et ce chantier était le moment de faire des affaires. Son idée était simple : puisque tous les documents du monde devenaient accessibles et se reliaient, il allait parcourir et indexer cette infinie bibliothèque. La science, la littérature, le commerce, la loi, la religion, la cuisine, tout. Ensuite, il ouvrirait la boutique du moteur de recherche, et il prévoyait de toucher des loyers sur chaque entrée de son index, mettant même les mots de la langue aux enchères, s’il vous plaît. Offre et demande, sable vendu aux Bédouins.
Ce que les gens espéraient désormais en enchérissant, c’était juste de pouvoir exister, d’avoir une petite place dans le nouveau monde. Apparaître en tête des résultats de l’index, sur une recherche, faisait la différence entre le néant et le quelque chose. Sauf que, comme tout le monde au début, la typote n’y avait pas cru, à ce projet. Pas bien compris ce qu’il racontait. Et puis ça ne lui plaisait pas tellement, cette idée que n’importe quel marchand puisse prendre les entrées du dictionnaire et en faire le gisement infini de sa richesse personnelle. Pour elle, le dictionnaire était un peu l’atlas de notre espace naturel. Un bien commun. Le marchand annexait le précieux bouquin, et le territoire infini de la langue qui va avec, comme ça, sans demander à personne, sans même le lire. Elle n’avait pas donné suite à sa proposition de le rejoindre. Elle préférait les livres, le silence, la lenteur de la lecture et la finitude des volumes.
Le marchand, en s’avançant, remettrait très bien la typote, il n’aurait pas oublié le temps de leur rencontre, car c’était aussi celui de ses débuts difficiles. Le bricolage, les premières listes de mots, glanées en ligne, les jours d’essais et d’échecs, les humiliations par les banquiers, les investisseurs. C’est alors qu’il l’avait reçue, car il voulait dès le début faire bien les choses, présenter mieux que les autres ces écrans si moches alors. Il voulait un écrin digne, fonctionnel, élégant pour son trésor. Il avait la prescience de ce qu’allait devenir son idée, sa firme. Il avait vu juste. Comme les mots aussi ont la vie brève, il s’intéressait toujours aux listes de « mots de l’année » ânonnées par les médias, c’était même son seul contact avec les dictionnaires, comme un bilan comptable. Pertes et profits. Alors, était-ce un bien, un mal (pour ses affaires), cette disparition ? Il n’aurait pas tranché cette question, et c’est peut-être pour cela qu’il serait venu. Pour ressentir, pour capter, pour avoir une nouvelle vision. Il pensait que lui, comme le monsieur du dictionnaire, suivait l’usage, la vie, et que si la vie changeait, que l’usage changeait, leurs deux produits changeraient aussi, le dictionnaire et le moteur de recherche. Les deux n’étaient que la trace de ce qui se pensait, s’écrivait et se disait, s’achetait, se regardait, ou s’écoutait.
Sauf que le lexicographe s’était efforcé de tout comprendre. Alors que lui n’avait pas besoin de comprendre quoi que ce soit. Le lexicographe devait tout refaire sans cesse, car produire une définition demandait de la souplesse, une personnalité capable de s’affirmer ou de s’effacer, de naviguer entre subjectif et objectif, de compenser le temps qui passe, et rien n’y était jamais complètement acquis. Alors que lui, il se contentait de regarder la machine rafraîchir le classement, et d’encaisser. Et tant qu’il y aurait des usages, enrichis ou appauvris, sa boutique tournerait. À tous les coups il gagnait. Il se sentait gaillard, boosté par les notifications en hausse du cours de sa société en bourse, vibrant dans sa poche.
Derrière le marchand souriant, la typote verrait enfin du mouvement. Un groupe d’enfants avec une adulte s’approcherait. Une chorale, une classe ? Une étudiante et un étudiant se tiendraient la main. D’autres encore : ceux-là, des bibliothécaires ? Il y aurait aussi une troupe de comédiens, et trois migrants apprenant le français. Suivraient des amateurs d’art et de belles choses, des amies, des amis, qui entoureraient son épouse, sa complice. On reconnaîtrait des silhouettes : artistes célébrités de la télé, de la culture, des célébrités sans visage de la radio aussi, un peu. Un chef sorti de sa cuisine, une factrice, un taulard, de vieilles joueuses de mots fléchés croyant que c’est pour le Larousse. Un dessinateur de bandes dessinées, des correctrices, plein. De vieux mandarins égarés loin de leur fac, un éditeur, venu avec son air gredin et une autrice au bras. Il y aurait un groupe de jeunes en survêtement. Une jeune femme jouerait de l’accordéon plus loin, assise sur un muret. Une foule se masserait, ignorant la typote et le marchand, qui s’effaceraient. Tout le monde serait là, ce serait coloré, calme et bienveillant.
Le monsieur du dictionnaire aidait à comprendre les mots des autres, à construire sa vie parmi eux et les liens qui font se tisser la société. Le monsieur du dictionnaire laissait l’esprit flâner et voguer librement dans ses pages, il y entremêlait les mots et les choses, le banal et l’incongru. Il racontait des histoires incroyables sur des notions courantes. Il était parfois facétieux dans ses exemples et faisait sourire. Mais, doucement grave, il redressait des torsions insupportables, aidait les discussions à sortir de l’ornière. Il ouvrait ses pages à tout le monde, pas pour faire populaire ou jeune, mais simplement parce qu’il prenait les gens au sérieux, et que son travail était pour eux. Il inspirait les poètes, scénaristes et dramaturges, les apprentis philosophes. Il écrivait pour qu’on écrive.
Et il y aurait encore des gens qui viendraient, beaucoup de gens.
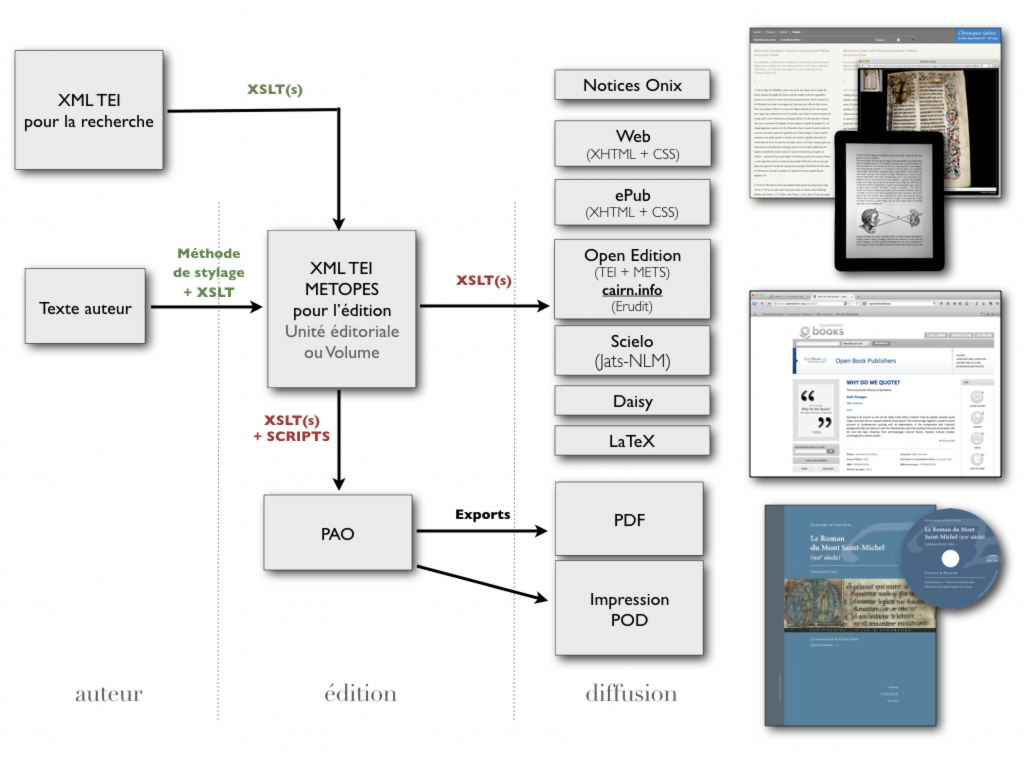
Il y a presque deux ans, je présentais ici le making-of d’une collection chez C&F éditions (la collections interventions, qui s’est étoffée depuis) produite avec des logiciels libres et en particulier dans un navigateur web, au moyen du code html, des feuilles de style css et du palliatif (ou polyfill) Paged.js qui supplée au manque de support par les navigateurs web de la spécification du W3C pour les CSS destinées aux médias paginés. Dans ce post (long), je voudrais raconter la suite des événements et faire le point sur l’état de mes travaux.
Le premier livre que nous avons fait avec Paged.js, (depuis quatre autres titres sont venus enrichir cette collection…)
Le procédé utilisé pour notre premier livre présentait des limites, que j’expliquais alors, surtout en ce qui concerne le flux de texte (le gris typographique, étant donné l’algorithme assez sommaire de justification et les césures souvent inopinées) ; mais sincèrement, on croise parfois des résultats équivalents, sinon pires, en librairie, dès lors que les logiciels PAO n’ont pas été correctement paramétrés. À noter aussi, l’absence de notes de bas de page, pas encore au point, mais qui finalement nous a permis de nous réconcilier un peu avec les notes de fin de section. Ces notes de fin demandent un peu plus de travail au lecteur, mais permettent d’avoir des pages finalement plus harmonieuses. Disons que c’est un arbitrage que nous n’aurions pas fait spontanément, mais que nous avons accepté.
Ce procédé est également tout à fait intéressant à plusieurs égards : d’abord il s’articule à une pratique que nous avons, de recourir massivement aux feuilles de style, toujours nommées de manière sémantique c’est à dire en référence à la motivation et non aux attributs visuels du texte ; ensuite, il nous donne une forme de contrôle, d’ouverture et de disponibilité en exposant le code source du livre dans deux langages que nous aimons pour leur lisibilité : html et css, il s’approche aussi de la publication epub qui est pour nous dans la continuité du livre imprimé, il nous permet aussi de travailler à plusieurs à distance avec git, sans se préoccuper des installations, des licences de logiciels de PAO, et ouvrant le chantier à des non-spécialistes de l’usine à gaz Adobe (comme mon collègue Hervé Le Crosnier ;-). Et puis enfin, il faut reconnaître que c’est irrésistible d’inventorier, de reconstituer et donc de repenser pas-à-pas ses besoins. C’est une bonne pratique de designer, qui permet d’évaluer chaque caractéristique, de prioriser, bref, de ne rien employer qui ne soit nécessaire, sous prétexte que ce serait disponible dans l’interface d’un logiciel.
Je pensais à la fin de ce chantier avoir fait le tour des difficultés principales et pouvoir faire des livres ainsi. C’était bien-sûr mettre de côté la complexité et l’exigence du média paginé, car il ne s’agissait pour le moment que d’un livre de texte simple. Ce qui est vrai pour une collection ne l’est pas pour toutes. La première ligne de crête franchie, je découvrais seulement de là-haut la vraie chaîne de montagnes que nous avions devant nous :-). Mais pour aborder tout cela il faut parler plus spécifiquement d’un autre projet. il s’agit d’avantage d’un manuel d’apprentissage, avec un chapitrage, mais aussi de nombreux éléments accompagnant le texte (figures, définitions, exemples, encadrés, listes etc.) qui viennent le compléter et qu’il est plus difficile de traiter simplement dans le flux du texte principal. Bref, nous voici repartis. Commençons par parler un peu de la manière dont les choses se font.
Des gens, des fichiers et des livres
Un des gros problèmes de la fabrication numérique de livres est l’articulation des différents moments et acteurs éditoriaux avec les logiciels et formats de fichiers. Avec l’auteur, on échange souvent des fichiers de traitement de texte (dans le meilleur des cas, on travaille en mode révision avec l’auteur, dans son traitement de texte, puis on accepte les révisions consensuelles, on y applique des styles, après avoir soigneusement nettoyé tous les enrichissements de texte plus ou moins inopinés). Cet échange ne se fait donc pas encore avec la mise en forme que permet le fichier de PAO, qui est quant à lui beaucoup plus difficile à échanger (pour des raisons de licence, de connaissance, et aussi de ressources à associer, comme les polices, etc). À Chaque étape, on peut avoir des besoins de correction, et la correction du texte peut impacter sa mise en forme à son tour. Une fois le fichier importé et composé dans un logiciel de PAO, on passe par une impression ou un PDF pour corriger des épreuves, mais au moment de décliner sur un autre format, on se trouve confronté au fait que la dernière version, corrigée, est devenue prisonnière du fichier PAO, et que la version de départ, dans le traitement de texte, est devenue obsolète.
Pour éviter ces problèmes, certains ont réfléchi à des flux de production à format pivot (single source). J’ai pu découvrir et pratiquer le flux Métopes de la Maison de la recherche en sciences humaines de l’université de Caen, qui s’articule autour du format pivot XML en TEI, avec des ramifications propriétaires pour coller aux usages de l’industrie : Word de Microsoft pour l’écriture et le stylage, Adobe InDesign pour la mise en page imprimée. Métopes, qui se constitue d’un ensemble de scripts et d’outils, insère entre les deux un fichier XML, qui permet de structurer et de créer ce qu’on appelle une expression, une source unique, interopérable pour toutes les manifestations (html, epub, imprimé, pdf, daisy, etc.). Ce flux apporte des possibilités très inspirantes, et son lot de contraintes : rigueur absolue du XML, double report d’une erreur découverte tardivement, difficulté à s’accommoder de besoins ad-hoc, et la nécessité d’une – relativement solide – formation. De toute manière, on échange pas de fichier XML avec l’auteur, on échange toujours du traitement de texte et des épreuves, et on se charge de reporter d’éventuelles corrections tardives à la fois en PAO et dans le XML.
Le flux Métopes de la Maison de la recherche en sciences humaines de Caen (Site web).
XML est très intéressant, mais s’articule avec des outils d’écriture (traitement de texte, notamment). Or on ne peut faire abstraction de l’aspiration à sortir des traitements de texte, de la multiplication d’outils alternatifs. Inspiré par le html et aussi par les langages de balisage léger, comme Markdown (qui permet de constituer une structure simple de html standard sans avoir à subir visuellement le code, et a été créé pour faciliter l’écriture, ce qu’on appelle le flow, d’un blogueur), je me suis demandé si on ne pourrait pas utiliser le flux html + css pour faire le livre, mais également, pour proposer des modalités d’écriture et d’inclusion de l’auteur et du designer dans un processus éditorial.
Il ne s’agit pas d’automatiser la mise en page, c’est un point sur lequel j’insiste, car les flux html + css ont tendance à faire fantasmer certains éditeurs qui se disent qu’ils vont pouvoir automatiser d’avantage, voire se passer de compositeur. À eux je souhaite bonne chance, surtout s’ils sont un minimum exigeants sur la qualité de composition. Non, c’est une autre manière de composer, tout comme markdown offre une autre manière d’écrire que Word, l’idée restant de fournir au compositeur une palette suffisamment complète pour lui permettre de bien travailler. Les gens, leurs savoir-faire ont toute leur place, et il s’agit plutôt de leur proposer une palette alternative suffisamment complète pour qu’ils et elles puissent s’exprimer.
Ici, il s’agit de permettre une collaboration plus serrée entre l’auteur et le designer-compositeur, en temps réel, avec autant d’itérations que souhaité. C’est utile pour un projet ou le designer intervient très tôt, ou bien quand l’auteur aime la contrainte de s’adapter à une forme finale pour écrire. Ce qui est fréquent par exemple dans la presse, avec des outils propriétaires comme par exemple inCopy d’Adobe, qui permet aux rédacteurs de voir la place assignée à leur copie dans la maquette, et l’état d’avancement des pages.
Bonjour Asciidoc
Mais si Markdown est pratique pour l’écriture de manuscrits simples, il est volontairement et à bon escient limité, et difficile à étendre. Cela signifie qu’il prend en charge des niveaux de titres, paragraphes, citations, listes, et en gros c’est tout. Pas de quoi ajouter des encadrés, des définitions, des exemples et autres éléments documentaires. Mon point de vue : gardons simples les choses simples. Il existe un langage du même type mais mieux adapté à la réalisation de documents structurés pour la documentation et les manuels : Asciidoc. Asciidoc n’est pas une nouveauté, c’est même plutôt un vieux de la vieille qui a été créé en 2002 (!). Il permet d’écrire en balisage léger et d’obtenir par compilation du html (il faut une petite extension pour avoir un html moderne et plus sémantique, car par défaut, Asciidoc produit un html un peu old school et surchargé). Avec Asciidoc, à nous les encadrés, les définitions, les exemples, les tableaux, et une infinité d’autres possibilités, puisqu’il est ouvert à nos propres catégories. Il s’avère donc à la fois beaucoup plus complet (avec l’inconvénient de demander un apprentissage, du coup), et plus extensible, permettant de créer des blocs personnalisés avec une syntaxe très simple.
Attention, ce n’est pas une entrée en religion que je propose ici, simplement Asciidoc est une forme qui me semble plus adaptée à notre type de publication. Le procédé décrit après peut tout à fait fonctionner avec d’autres langages, html, markdown ou autres…
À gauche, le chapitre en Asciidoc, à droite, son rendu avec Paged.js. Nous allons détailler un peu dans cet article ce qui se passe entre les deux, dans ce type d’ouvrage.
J’ai donc commencé par tester si le contenu du manuel que j’avais en projet, et dont l’auteur, Wendy Mackay souhaite avancer l’écriture avec moi, pouvait fonctionner en Asciidoc. Il se trouve que ça convenait vraiment bien. Je n’entre pas dans le détail ici, j’y reviendrai peut-être. L’important à comprendre est que l’auteur peut structurer sémantiquement son manuscrit de manière assez fine, sans avoir à se préoccuper de la mise en forme. Avec une petite astuce, à chaque sauvegarde, on compile le html et si on veut, on le prévisualise dans un navigateur web, avec par exemple un feuille de style css paginée. On s’y croirait.
Le retour des styles
Pas tout à fait. Le stylage ne peut être entièrement automatique, même si une feuille de style assez élaborée a été préparée en amont, il y a parfois des arbitrages à faire, des petites adaptations locales, en particulier avec l’imprimé, car la page, et la double-page, avec leurs limites strictes en hauteur et largeur, leurs marges, imposent leur format, au contraire du scroll infini et de l’élasticité de la page web. Comment donc le compositeur peut-il introduire des changements locaux nécessaires au « calage » a posteriori de sa double page, sans venir mettre sa pagaille dans le manuscrit ou le code source du texte lui-même (en y ajoutant ou déplaçant des éléments, non pas selon les critères logiques, mais selon les critères esthétiques et de plus contingents liés au format précis de sortie).
J’ai pour cela introduit une troisième source. On se retrouve avec trois fichiers : le manuscrit balisé sémantiquement au moyen de Asciidoc, donc, obéissant à sa propre structure, en sections, paragraphes, d’une part, la feuille de style CSS générale d’autre part, qui s’occupe de construire le livre, et une autre CSS liée à la sortie dans un certain format qui permet de cibler certains éléments et de leur ajouter un ajustement local a posteriori.
Le problème est qu’il faut à cette feuille de style pouvoir cibler tous les éléments. Certains sont faciles à attraper au moyen des sélecteurs et en particulier des pseudo-classes :nth… d’autres sont plus difficiles, parce que la structure du code html est profondément modifiée à la volée par Paged.js lorsqu’il crée des pages, découpe le contenu, lui donne de nouveaux contenants…
J’ai donc profité des « hooks » que permet Paged.js, un système astucieux conçu par le brillant développeur Fred Chasen, créateur de Paged.js, qui permet d’insérer ses propres instructions à différents moments dans la chronologie de son traitement du contenu, de son découpage, de sa mise en forme. Pour commencer, afin d’ajouter une petite routine qui repère et identifie certains éléments (figure 1, 2, 3… exemple 1, 2, 3, définition 1, etc.), ainsi que les sections et sous-sections. C’est encore un peu ad-hoc mais on peut l’imaginer personnalisable. Une fois cet étiquetage fait, il est possible d’attraper un élément et de changer ses attributs, dans une feuille de style séparée, nommée tweaks, car réservée aux petits ajustements localisés et circonstanciels.
(récréation) Reload-in-place
Pause : ma première petite fierté est une broutille qui change la vie. Comme vous le savez, lorsqu’on fait une modification de texte ou de style, il faut recharger une page web dans le navigateur pour voir les changements. Avec une page web ordinaire, le navigateur recharge la page, puis se repositionne là où il était dans la page si on avait scrollé. Mais dans le cas d’un livre paginé, il ne le fait pas et se positionne en haut, page 1. C’est embêtant, lorsqu’on corrige la page 128, de devoir sans cesse recharger, attendre puis aller la retrouver à la main, cette page 128, pour voir si la correction est bien apparue.
J’ai donc ajouté une petite extension à Paged.js qui permet après le rechargement, de rejoindre automatiquement, et le plus vite possible la page 128 (ou une autre, sans supplément de prix ;-), sans attendre que la compilation totale du livre soit effectuée. Je vous l’offre, car je la considère indispensable pour mettre au point un livre. On recharge et l’affichage revient là où on en était, sans attendre que le livre entier soit compilé. Indispensable (fin de la pause).
Dans cette petite vidéo, on voit que si on va sur une page, puis qu’on recharge le navigateur, la fenêtre rejoint automatiquement cette dernière page vue, pendant la compilation Paged.js.
Traits de coupe, débord et double page
Une nouveauté du dernier titre de la collection interventions, c’étaient des intercalaires illustrés en double page entre les parties du livre. J’ai pu bénéficier du travail de Julie Blanc et Julien Taquet sur l’interface de Paged.js qui proposent de faire apparaître une zone de débord autour de la page, avec des traits de coupe.
Pour mettre une image en double page, j’ai en réalité positionné deux grands blocs, un sur chaque page, débordant dans la zone de coupe, et importé deux fois mon illustration. La feuille de style calcule, en fonction de la présence de ce type de bloc sur la page de gauche ou de droite, le décalage d’image qui permet de positionner les deux morceaux bord à bord. Vive les css calc() et les variables.
Une double page avec illustration sur deux pages, débords et traits de coupe (on ne les voit pas bien avec cette trame, mais ils y sont).
Mais la présence de cette zone de débord, avec les traits de coupe directement dans Paged.js (et non plus ajoutés a posteriori au PDF) permet d’envisager et de réaliser toutes sortes de nouvelles disposition qui sortent de l’empagement, et donc du livre de texte pur et dur.
Encadrés
La deuxième chose nouvelle dont j’avais besoin pour ce projet, c’étaient des blocs qui glissent hors du texte, dans la marge, mais avec des comportements parfois différents. Certains, comme des notes marginales doivent suivre le paragraphe auquel elles sont ancrées. C’est le cas ici aussi pour les légendes de figures. Pour ces éléments, j’ai opté pour un positionnement absolu, relatif à leur parent (pour la hauteur) et un comportement légèrement différent sur les pages de gauche ou de droite, avec le même résultat, ils sont dans la marge extérieure (le grand fond).
Mais d’autres sont un peu différents. On peut imaginer des encadrés, qui se positionnent de manière absolue dans la marge, par rapport à la page, et non à leur point d’insertion dans le manuscrit. Mais il peuvent aussi être plusieurs, et dans ce cas, il ne faut pas qu’ils se superposent mais bien qu’ils se juxtaposent. J’ai opté pour la création d’un conteneur pour eux dans la zone de marge de Paged.js elle-même, un hook les retire du flux de texte et les déplacer, un par un, dans cette zone.
C’est un troisième type d’encadré qui pose le plus de difficulté finalement, les grands encadrés insérés dans le texte lui-même. En effet, ces grands encadrés trouvent une place précise dans le manuscrit, mais dans une page, ou double-page, ça ne se passe pas comme ça…
Sur ces quatre pages, de gauche à droite, quelques exemples éléments qui peuvent venir dans la marge : 1. à gauche, la légende de la roue colorée apparaît à la hauteur de la figure, comme 4. les notes marginales qui sont bien alignées sur tel ou tel paragraphe. Mais au centre : 2. La liste est positionnée en haut de page et 3. l’encadré aussi.
Flottements
Tant qu’un livre ne contient qu’un texte en effet, tout se passe bien, mais certains éléments (textuels ou iconographiques) ont un statut particulier qui peut les détacher du texte. Il peut s’agir de notes par exemple, dont on voit bien qu’elles sont un renvoi au sein du texte principal vers un petit fragment de texte qui en est précisément extrait pour être renvoyé à la fin de l’ouvrage, de la section, ou bien, et c’est là que ça devient intéressant, à une région particulière de la page : en bas pour les notes de bas de page, ou dans une marge pour des notes marginales, des gloses…
Ce n’est pas tout : il y a aussi des figures, tableaux et certains encadrés qui figurent dans le texte mais ne tombent d’ailleurs pas toujours bien, une fois placés dans l’espace borné de la page. Par exemple, un encadré peut arriver à cheval sur deux pages. Dans ce cas, il faut la sortir du texte, et le faire « nager » jusqu’au haut de la page suivante par exemple, tout en faisant passer une portion de texte correspondante, sous l’encadré, pour la rattacher au texte la précédent et combler le vide. Cela se fait en PAO au moyen des blocs ancrés, et avec LaTeX des éléments flottants (floats). En CSS, la chose est aussi prévue depuis 2015, avec des possibilités très intéressantes, mais pas du tout implémentées pour le moment. Paged.js pourrait s’y pencher prochainement. En attendant, pouvions-nous y palier au moyen d’un de ces Hooks ?
L’encadré gris était coupé, à cheval sur deux pages. On va plutôt le positionner en haut de la page suivante et faire passer tout un titre et un paragraphe « avant » lui pour éviter un grand blanc en bas de la page de gauche, si la lecture le permet.
Encore une fois, j’ai pu bénéficier du travail de de Julie Blanc qui s’intéresse à la question depuis un moment et avait déjà publié un article complet et même un petit script pour pousser les encadrés en haut de page suivante dans une de leurs précédentes expérience. J’ai de mon côté travaillé dessus pour obtenir deux modifications importantes à mes yeux : d’une part plusieurs possibilités (quatre en tout, pour atteindre les quatre extrémités de la double page, décrites ainsi : la même page en pied, et en tête, la page suivante en pied et en tête – on ne peut pas revenir à la page précédente, déjà composée par le script, et d’autre part, une manière de le faire correspondant à mon approche, en effet je ne pouvais me permettre de déclencher cette migration par l’ajout d’une classe dans le html. Laissez-moi vous expliquer pourquoi.
Les scripts proposés par les talentueux développeurs de Paged.js Julie Blanc et Julien Taquet s’appuient souvent sur une classe qui déclenche tel ou tel comportement, c’est simple, efficace… mais c’était précisément en contradiction avec ma ligne directrice : essayer de ne pas avoir à changer l’ordre des éléments dans le texte / code source, ni d’ajouter de classe motivée par le graphisme, de classe qui ne soit pas sémantiquement justifiée dans le manuscrit source. Ce source, qui est en Asciidoc et même pas en html, dans un format d’écriture, donc, que j’essaie de réserver à l’auteur.
La ligne du parti
C’est bien une opération intentionnelle du compositeur qui permet de sortir un bloc du flux de texte et de choisir sa destination. Une decision au vu de la double page, d’en améliorer l’aspect. J’ai donc proposé une css dévolue à cet usage. Le designer dispose ainsi de deux feuilles de style : une pour la composition générale, et donc « automatique », applicable à l’ensemble du manuscrit, et cette autre, nommée tweaks.css pour procéder à des ajustements au vu du résultat une fois composé. Même si on peut définir des règles automatiques pour ne pas couper une figure, la décision sur l’emplacement d’un bloc en « page float » se fait à ce moment là, a posteriori. Tout comme peuvent l’être d’autres détails et petits ajustements qui permettront de gagner deux lignes par ici, aligner un élément sur un autre, ou à l’inverse de le pousser un peu plus loin. L’idée est de bien retrouver les deux temps de la composition : celui que le designer consacre à l’élaboration de son gabarit et de ses feuilles de style, et qui vont accueillir le contenu dans l’espace de la double page, et celui où il décide, au vu du rendu de telle ou telle page, de procéder à quelques aménagements. On peut tout à fait imaginer que l’auteur fait de même de son côté, en modifiant un peu son manuscrit en fonction de l’aperçu qu’il obtient de son texte une fois mis en page (par exemple pour équilibrer la longueur de deux définitions, pour parce qu’une légende prend trop de place, etc.) En effet, certains auteurs écrivent avec des contraintes de forme, soit parce qu’ils aiment ça et que ça les stimule, d’écrire pour tel ou tel cadre, soit parce que leur media les y contraint franchement (les rédacteurs de presse se reconnaîtront). Nous avons ces quatre temps actifs de publication :
le temps de la rédaction (et de l’illustration)
le temps de la maquette
la retouche par le rédacteur
la retouche par le compositeur
L’auteur et le designer travaillent ensemble sur le livre, chacun a ses fichiers. Au vu de la mise en page, chacun peut décider de changer des choses, l’auteur peut couper du texte par exemple, le designer peut déplacer des éléments, ajuster localement ses règles de mise en page, mais en évitant d’intervenir dans le fichier de l’auteur pour cela.
Chaque temps s’effectue autant que possible dans le fichier le plus adapté, ce qui évite à un des acteurs d’avoir à trouver des modifications inopinées, venues d’un tiers, et une syntaxe qui ne lui appartiennent pas dans son fichier. Cela simplifie en outre la gestion de versions de fichier, puisque cela réduit les risques de conflit de version (les fichiers sont synchronisés entre auteur et designer via NextCloud à ce stade). On peut imaginer un éditeur de fichiers qui donne à chacun un espace de travail sur ses fichiers et un aperçu commun du résultat.
De gauche à droite, les fichiers, le texte source qui va donner le html (et que l’auteur a appris à écrire en Asciidoc), la css principale qui donne les règles de la mise en page, et la css de « tweaks » qui permet de modifier la position et l’apparence de certains éléments de la page a posteriori. Tout est synchronisé via NextCloud pour le moment, et comme chacun s’occupe de ses fichiers, ça fonctionne sans accroc, même si on peut améliorer.
Tout ça est bien en théorie, en pratique c’est plus difficile. D’abord le fait d’utiliser une compilation en html5s pour le html rendu à partir d’Asciidoc fait perdre les identifiants. Asciidoc étiquetait de manière assez utopique, tous les éléments au moyen d’un id numérique. Utopique puisque chaque modification (ajout d’un paragraphe par exemple) modifiait l’ensemble des numéros (Paged.js fait de même). Mais pour que la css tweaks du designer fonctionne, il faut que celui-ci puisse désigner (sélectionner en terminologie css) de manière fiable et pérenne l’élément visé.
Attrape-moi si tu peux
Une syntaxe permet en théorie de se passer d’identifiants, les sélécteurs de type nth-child qui combinés avec des chiffres et lettres, permettent en théorie de cibler des éléments sans classe et sans nom par exemple l’avant dernier paragraphe de la troisieme section s’écrirait :
Cela convient dans certains cas (bien que peu pérenne, un changement en amont pouvant bousculer ce comptage) et ça s’applique assez bien au DOM du code source du manuscrit. Mais c’est plus difficile avec le DOM paginé une fois rendu par Paged.js. Un exemple : Paged.js coupe les sections au fil des pages, et c’est bien normal, mais, il les réécrit au sein de chaque page. Ces sections se retrouvent donc multipliées dans le DOM, autant de fois qu’elles parcourent de pages. Ainsi un document d’une section sur six pages contiendra six pages avec six sections enfant. ça complique vraiment les choses pour compter au vu du résultat, et ça bouge pas mal.
J’ai donc commencé par créer une petite routine en Hook qui attribue un ID correspondant à la numérotation des éléments, figure 1, figure 2,… tableau 1, tableau 2,… exemple 1, exemple 2. Les sections aussi sont identifiées en fonction du nom de leur titre (h2) et de leur numéro d’ordre. Ainsi il devient possible de cibler une figure, pour lui assigner une propriété page-float, dans l’idéal. Car comme cela n’existe pas encore vraiment, j’ai besoin d’une classe pour déclencher le script. Ça donnerait donc en théorie :
#image-block_5 { <br> .page-float-next-top; <br> /* on ne peut pas faire ça */ <br> }
Mais on ne peut pas inclure une classe CSS dans un ensemble de propriétés comme on peut le faire en LESS ou SASS par exemple, ce qui serait pratique. De toute manière ce que fait LESS dans ce cas est simplement d’aller chercher les propriétés et leurs valeurs de la classe indiquée et de les rapatrier dans l’ensemble qui les appelle. Il n’étiquette pas l’élément du DOM avec ladite classe. Or c’est ce qu’il me faudrait : partir d’une css pour ajouter une classe dans le DOM.
J’ai donc (avec l’aide de Julien Taquet, parce que tout seul j’aurais eu du mal) écrit un petit script qui s’exécute juste avant Paged.js et qui va ajouter ces classes dans le DOM en fonction de ce qui est déclaré dans tweaks.css pour que Paged.js (et son hook consacré aux page-floats) les repèrent et opèrent le substitut de page-float. Pour cela, et à titre de preuve de concept, j’ai donc carrément créé une propriété css à moi (propriétaire donc), qui serait à retravailler sur le modèle du working draft du W3C, mais qui très temporairement s’appelle –taffin-page-float, et qui peut prendre quatre valeurs : same-top, same-bottom, next-top, next-bottom. ce qui donne dans tweaks.css
et qui permet à la fois d’ajouter la classe dans le DOM, sans intervenir sur le manuscrit, puis de déclencher le comportement du hook réservé à ce type de page float (position en premier dans le contenu de la page suivante : en gros, les blocs qui vont en haut sont déplacés par le script, ceux qui vont en bas sont positionnés de manière absolue). Ouf. Ça parait un peu compliqué comme ça, mais cela suit la logique proposée, et ça marche, modulo une bonne gestion de la chronologie des événements par le script. Je ne remercierai jamais assez Julien Taquet pour son aide et sa fine connaissance de Paged.js.
La partie du petit script qui modifie les éléments du html en fonction de la valeur qu’il trouve pour la propriété –taffin-page-float
Sur cette base et quelques bugs plus tard, j’ai pu produire mon chapitre de manuel, avec grosso modo tous les petits raffinements nécessaires. Je voulais documenter un peu l’approche, c’est pour cela que j’ai écrit ce post.
Un dernier petit avant-après pour la route.
Prochaines étapes
Les codes sources sont ouverts et je peux les proposer à la communauté, je les ai déjà transmis à mes complices à qui je suis tant redevable, comme je l’ai fait pour le Reload-in-place si utile au quotidien, même si je voudrais encore prendre le temps de finaliser des choses avant, et notamment changer le fonctionnement (et le nom) de la propriété propriétaire :-)
Je voudrais aussi confronter ce fonctionnement à d’avantage de chapitres / modèles, bref, prendre un peu de temps, car c’est ainsi que les choses se consolident, se complexifient, puis se simplifient. Pas si évident de contribuer utilement à un projet libre, c’est un investissement important et le syndrome de l’imposteur guette.
Mais enfin, l’idée est maintenant de se glisser dans un flux, un éditeur un peu plus intégré, soit en s’appuyant comme je le fais actuellement sur une plateforme, comme VSCode, soit de préférence en utilisant le navigateur web comme environnement de travail. Là encore je ne suis pas le seul à y penser, il y a par exemple l’astucieux printcss.live de Andreas Zettl, Stolon de Raphaël Bastide, ou même Editoria. Il serait possible de partir d’une base et de la modifier à titre de contribution, quand la licence le permet. Car tout cela ajoute un autre niveau de complexité (gestion des fichiers et des droits essentiellement) et j’aurai besoin d’aide. Voilà voilà, pour le moment, désolé pour le long post. Questions ou commentaires bienvenus !
Ce a quoi pourrait ressembler un éditeur connecté, permettant à l’auteur d’écrire, et au designer de mettre en forme, ensemble et simultanément. Y’a plus qu’à.
Le 2 décembre 2020, Olivier Taffin, mon père, est mort à Marseille où il habitait, cédant à son emphysème pulmonaire. J’étais si habitué à nos petits rituels de papa et de fiston, au fait qu’il avait une vie publique bien avant moi, à nos conversations, même discontinues, à sa manière de vouloir toujours parler de l’essentiel tout en essayant de nous rassurer, et donc d’esquiver en souplesse, que j’en ai oublié de dire qui il était. Je ne pensais pas qu’il avait besoin de moi pour ça. Je me suis peut-être trompé. Et c’est peut-être moi qui en ai besoin. Alors je vais jeter trois mots ici. Des impressions plutôt que des faits, qu’on trouve bien listés sur sa page Wikipedia. Ou des images, il y en a plein de ses toiles sur son site, et pour la BD je reviendrai bientôt.
Olivier avait soixante quatorze ans et était artiste. Il avait plusieurs modes d’expression et de création, trop peut-être, pour dire en une fois : peintre, sculpteur, cinéaste, dessinateur, auteur de chansons, de romans, de théâtre et d’opéra, prof municipal de dessin, et peintre encore, chanteur enfin, pour ce dont je me souviens. Mais moi je l’ai connu tard, déjà, à vingt quatre ans. J’ai manqué ses années 50 et 60…
Il n’était pas artiste pour le plaisir de faire des choses créatives avec ses doigts, il était artiste de cette nécessité intime et violente qui rend le travail artistique lui-même pénible. Avec ses obsessions, sa difficulté à s’y mettre, son angoisse insoluble dans la bière ou le jaja, ses cigarettes fumées accroupi à évaluer ses créatures en devenir posées sur les tomettes. Il était artiste pour guérir ses plaies de l’âme, son adolescence pénible, la perte de son frère, ses espoirs déçus, mais jamais trahis, d’utopiste né à nouveau en 1968, son désir frustré de reconnaissance, autonome par contrainte, mais indépendant par volonté, érotomane de l’imaginaire, retourneur d’images, amoureux de paroles, de sa femme, de son quotidien, de ses enfants. Nostagique plusieurs fois expulsé de son passé.
Pris dans ses nécessités intérieures, il peinait à choisir son champ, à chercher à plaire, à communiquer ses œuvres, et à s’insérer dans le monde organisé des choses identifiées. Il s’appauvrissait à force de chercher partout sauf là où est l’argent, même dans le monde de l’art. Il ne savait pas se faire entreprise, obtenir des subventions, plaire aux dracs. Il produisait peu, ruminait beaucoup, prenait son temps sans vraiment le vouloir. Ce temps, qu’il préférait toujours à l’argent, en faisait quelqu’un d’abordable dans un monde de gens pressés, un peu comme dans un film où tout le monde passe en accéléré sauf un personnage qui est au ralenti.
Angoissé plus que bougon, désespéré, doux, attentif, curieux. C’est un drôle d’équilibre, de mélanger tout ça avec l’exigence d’authenticité et le refus des concessions. Sa manière d’être père : me recadrer à chaque fois qu’il sentait que je me perdais de vue ou me trahissais par des choix superficiels ou une attirance pour la facilité, et me câliner quand je lui annonçais un truc comme un ènième redoublement… Un peu Jedi, mais sans la mystique.
Car l’enfance est le lieu des mythologies. Vous en voulez ? J’ai déjà raconté le paradis perdu de ma petite enfance, en 2005, mais j’ai encore de l’épique en tête. En voilà un paragraphe. Quand il m’apprenait à faire bouger les dessins dans un petit carnet rien qu’en le feuilletant, et aussi avec une caméra super 8. Quand je déballais fièrement un malabar dans la cour de récré pour montrer à mes copains le petit comic qu’il avait fait dans l’emballage. Mes mercredis, samedis et dimanche dans l’atelier de BD de l’impasse Bergame, que je passais dans la mezzanine au dessus des dessinateurs Cabanes, Lacaf, Loisel, qui inventaient avec lui la BD pour adultes, et lisant des choses pas du tout de mon âge en respirant leur fumée. Des soirs sous l’édredon, avec un peu de buée qui sort de la bouche, lisant à la lueur de la lampe à pétrole quand EDF avait coupé l’électricité, ou quand le proprio esthète venait se servir en tableaux pour suppléer au loyer. Quand je m’endormais dans les fêtes et les vernissages après avoir bien mangé. Mais malgré ça j’étais tellement gâté, le boîtier Olympus d’occasion pour faire mes premières photos, l’apprentissage du labo pour les développer, ou l’ordinateur Sinclair alors que je réclamais depuis des mois une console comme les autres gamins : « Tu n’as qu’à les programmer, si tu veux des jeux », cadeau comploté avec ma mère, quand ils étaient divorcés mais encore alliés pour me faire plaisir. Je me souviens de ma bouderie quand il reconstruisait sa vie avec Cornelia et que moi je l’aimais bien, la galère bohème d’avant. Ces journées France Inter. Je me souviens de nos voyages invraisemblables, en 2CV enfant, ou en DS adolescent avec le vomi du chat et de Juliette en alternance continue. Ou de cette transhumance dans un camion fou avec Richard pour poser la famille et ses meubles expulsés de Paris à la campagne. Cette belle maison au bord de la rivière, ses filles Juliette et Lucie heureuses et musiciennes, que je voyais de moins en moins. Je me souviens du jour où il voulait revenir à Paris mais n’en avait plus les moyens immobiliers, que je lui ai dit : « Tu devrais aller voir Marseille, ça te plairait, c’est pas la province, c’est autre chose, un peu comme le vingtième ».
On pouvait se confier à lui, sur l’essentiel. Qu’on soit une enfant, un adolescent, un adulte ou une vieillarde. L’accessoire l’intéressait peu. Personne se s’y trompait et il avait de nombreux amis d’une vie, indétachables, ou copains d’un comptoir. Il devait aussi faire fuir, pour ces raisons, celles et ceux que ça angoisse et qui préfèrent se blottir au creux des choses. Les autres, il les régalait avec des délices de la table, si centrale que la journée entière s’organisait autour d’elle.
Un portrait pareil est sans doute raté : j’imagine que celles et ceux qui le connaissent déjà le trouveront un peu ressemblant, et qu’il restera un mystérieux brouillard pour les autres. J’ai vécu toute ma vie jusque là avec un Olivier splendide arbre dans mon jardin mental. Je ne me rends pas encore vraiment compte de ce que va donner la vue sur l’autoroute, maintenant qu’il est abattu. Je pense à ses amours, les mères de ma vie, mes sœurs, ses petites filles.
[màj] Au cours du mois de décembre 2020, si vous souhaitez participer à ses obsèques, vous pouvez vous joindre à une petite cagnotte.
François Houste est un type formidable : non seulement il a du talent et de la finesse, mais en plus travailler avec lui est un grand plaisir. C’est sans doute pour cela qu’il inaugure la collection fictions de C&F éditions ;-)
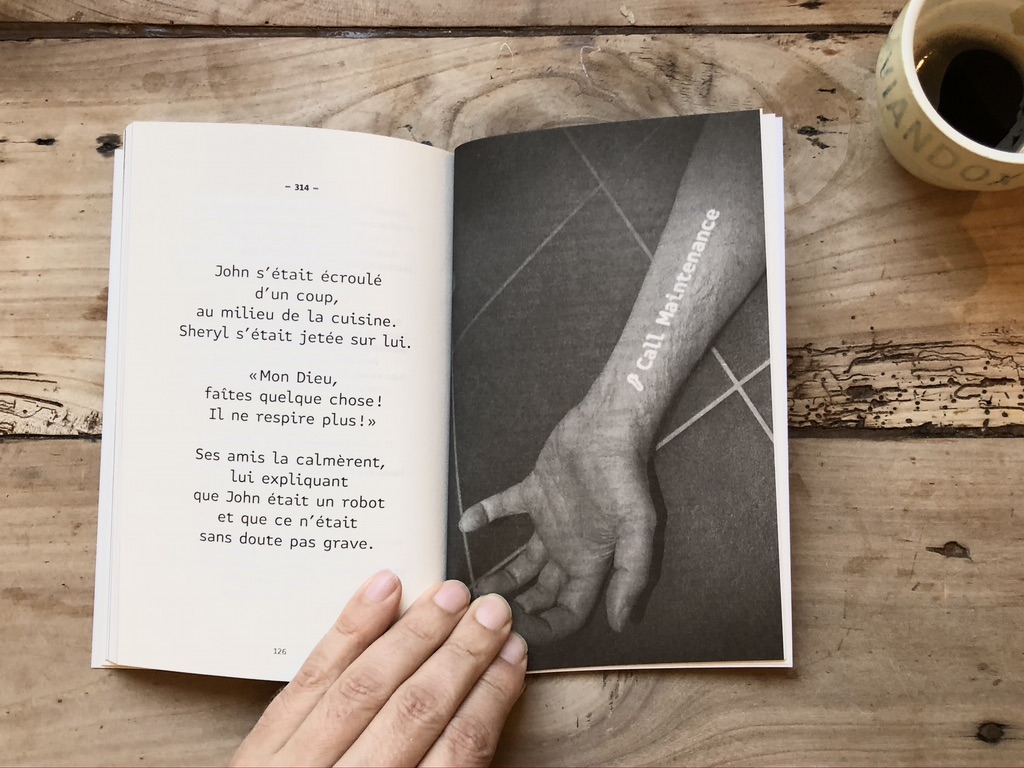
Mikrodystopies, ce sont des moments volés au futur (un futur si présent), des situations, plus que des histoires, qui montrent les humains confrontés à leur devenir-machine, les algorithmes face à des dilemmes humains trop humains, les robots désireux de se faire une place dans l’humanité, bref, un joyeux méli-mélo de notre quotidien techno-futur. 320 fragments de vies, tous limités à 280 caractères – pas un de plus – un exercice de style inspiré et stimulé par Twitter où le compte @mikrodystopies poursuit ses explorations. Le ton est toujours aigre-doux, plein de finesse, d’humour aussi. Quant au désespoir, n’est pas une injonction, il est laissé à la discrétion du lecteur, qui affichera d’abord bien souvent un sourire.
Le livre, lui, s’est composé avec beaucoup d’harmonie dans les échanges : sélection de petits fragments, ajouts, retraits (quand on ressentait des répétitions à la lecture), déplacements, corrections, choix du caractère (le magnifique faux monospace Attribute Text de Viktor Nübel) et mise en forme (la composition est centrée, et rythmée manuellement, ligne par ligne, imitant une diction, réalisée avec Sophie Harris) ; tout cela se faisait avec décontraction et une vraie complicité auteur-éditeurs. La couverture finalement choisie représente comme sur la vieille VHS du salon, cette faculté d’avance-rapide-jusqu’à-la-fin que nous procure le livre.
Mais j’avais en tête une série de photos depuis un moment, cela a été l’occasion de passer à l’acte. L’idée en était : produire « à la maison » et sans effets de retouche, ni collages impressionnant, ni équipements futuristes, des images mettant en situation tous ces messages numériques qui nous confrontent aux erreurs systèmes, illegal arguments et autres plantages, violations des termes, acceptation de conditions abusives ; bref, à la régulation de nos vies par les logiciels depuis que « Code is law ». J’ai donc profité de l’occasion pour acquérir un nano projecteur à trois sous que j’ai rendu complètement myope en lui collant deux bonnettes. Puis j’ai préparé des messages que nous avons pu projeter, avec l’aide de ma fille, sur les jouets, murs, objets de la maison, ou même sur notre propre peau, comme s’ils étaient animés de facultés interactives nouvelles, irrigués de silicium. Avec un peu d’imagination, bien-sûr. C’était amusant de se contorsionner avec tout cet équipement dans des petits coins de la maison. J’ai aussi pu faire quelques images chez ma mère, dont l’intérieur n’a vraiment rien de techno, et lui proposer ainsi une belle mise à jour. Bref, on était vraiment dans le quotidien familial, tout près des récits de François Houste.
Je me retrouvais avec une série de 11 images finales, sombres mais familières, qui ont rapidement trouvé leur pendant dans les Mikrodystopies. Plus que des illustrations strictes, cela composait des paires harmonieuses, que nous avons mises en valeur dans certaines doubles pages du livre.
Techniquement, nous souhaitions aussi conserver le lien entre le fragment et le tweet d’origine sur le compte @mikrodystopies. Chaque fragment a été numéroté, et l’auteur a bien voulu nous transmettre l’URL du tweet originel. Avec cette table des tweets utilisable en ligne, il était ensuite possible de conserver un lien entre la version imprimée et son pendant en ligne, par exemple pour réagir, retweeter ses préférés, etc.
Nous avons aussi imaginé d’autres possibilités, comme celle de proposer aux lecteurs et lectrices de produire leurs propres mikrodystopie, en texte ou en image, cela va se passer ici très prochainement https://cfeditions.com/mikrodystopies/
À noter : l’auteur dédicacera son livre à l’occasion d’un pot de parution à Paris -> jeudi 24 septembre, entre 18h30 et 20h, au 28 rue de Lagny, 75020 Paris. Apéro, masques et gestes barrières en prime.